Po ostatnim przedstawieniu mojej starej aplikacji AnimalShleter biorę się za jej przepisanie na nowsze technologię. Backend będę chciał postawić w oparciu o Springa, a warstwa wizualna zostanie wyrzucona do Angulara. Dodatkowo jest w planach wystawienie usługi do wysyłki maili poprzez brokera wiadomości. Do łączenia z bazą danych będę wykorzystywał JdbcTemplate, aby ograniczyć magię Hibernate’a. Oczywiście trzeba napisać więcej kodu, ale jednak mamy większą kontrolę nad naszym kodem. Będę też wykorzystywał Liquibase do trzymania zmian schematu bazy danych oraz skorzystam z Vavr, aby pisać kod w sposób bardziej funkcyjny.
Na tą chwilę mam zamiar tylko przepisać wszystkie funkcjonalności znajdujące się w starej aplikacji. Jednak kto wie, może zacznę dodawać coś więcej w późniejszych etapach projektu. “Pożyjemy, zobaczymy”, ale na razie czas zabrać się do roboty.
Lista wszystkich wpisów dotyczących projektu AnimalShelter:
#1 - Opis projektu AnimalShelter
#2 - Pierwsze kroki w backendzie
#3 - Refactoring i prace rozwojowe części serwerowej
#4 - Tworzenie GUI w Angularze
#5 - Zatrzymaj się, przemyśl i zacznij działać!
#6 - Pomysł na architekturę
#7 - Wykorzystanie CQRS
#8 - Ponowna implementacja
#9 - Rozterki architektoniczne
#10 - Podsumowanie + implementacja wysyłki maili
#11 - Programowania ciąg dalszy
#12 - Dopinanie zadań do końca
Inicjalizacja projektu
Zacznijmy od wejścia na stronę start.spring.io, gdzie w łatwy sposób możemy sobie projekt Spring Boot’owy. Oczywiście mając Intellij w wersji Ultimate możemy to samo uzyskać z poziomu IDE.

Tworzenie projektu Spring’owego z poziomu przeglądarki
Wcześniej już zaszufladkowaliśmy tą aplikację jako CRUD, więc zacznijmy od zdefiniowania endpointów. Mam świadomość, że taki CRUD można załatwić jednym interfejsem CrudRepository dostarczonym przez Springa, ale będziemy jeszcze tutaj dokładać dodatkowe funkcjonalności poza zwykłym zapisywaniem do bazy danych. No dobrze to jak będziemy mogli dostać się do naszej aplikacji.
- GET /animals - pobiera wszystkie zwierzęta będące w schronisku;
- POST /animals - dodaje nowego zwierzaka do schroniska;
- GET /animals/{id} - pobiera dane zwierzaka o podanym id;
- PUT /animals/{id} - edycja danych zwierzaka o podany id;
- DELETE /animals/{id} - usuwa wybranego zwierzaka o podanym id;
Na razie myślę, że tyle wystarczy. Teraz zapiszmy sobie naszą podstawową tabelę, w której będziemy trzymać naszych pupili. Nazwiemy ją po prostu “animals” i na nią będą składały się następujące kolumny.
- id - identyfikator zwierzaka;
- name - imię dla naszego pupila;
- kind - rodzaj zwierzaka;
- age - wiek zwierzaka;
- admittedAt - data, kiedy nasz pupil został przyjęty do schroniska;
- adoptedAt - data, kiedy nasz zwierzak został adoptowany;
Postawiłem na MySQL, ponieważ z nią miałem najwięcej do czynienia, ale dla naszej aplikacji nie będzie to miało większego znaczenia. No to zabieramy się do kodzenia!
Pierwsze efekty prac
Na tą chwilę konfiguracja moich beanów wygląda następująco.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Configuration(proxyBeanMethods = false)
public class AnimalConfig {
@Bean
public AnimalRepository animalRepository(JdbcTemplate jdbcTemplate) {
return new AnimalRepositoryImpl(jdbcTemplate);
}
@Bean
public AnimalService animalService(AnimalRepository animalRepository) {
return new AnimalServiceImpl(animalRepository);
}
}
Zdefiniowałem, że pod interfejsem AnimalRepository będę korzystał z konkretnej implementacji wymagającej do działania JdbcTemplate. Początkowo miałem też zdefiniowany bean dla JdbcTemplate, ale okazało się, że jest on zbędny. Następnie mamy zdefiniowane jaka implementacja serwisu ma być wykorzystywana w aplikacji. Do jej działania potrzebny jest obiekt AnimalRepository, dlatego podajemy go jako parametr metody. Zdecydowałem się na napisanie klasy konfiguracyjnej, aby nie oddawać całkowitej władzy Springowi. Chciałem przez to sprawdzić w jaki sposób możemy odseparować się od frameworka, czy jest to skuteczne działanie. Zachęcam Cię do zapoznania się z moim wpisem, który rozprawia nad różnicami pomiędzy @Bean a @Component.
Dodatkowo wykorzystałem też profilowanie aplikacji dzięki czemu przez podanie parametru -Dspring.profiles.active=dev jestem w stanie odczytywać właściwości deweloperskie. Robi się to naprawdę prosto, wystarczy zdefiniować plik o nazwie application-dev.properties, czyli wartość po myślniku musi odpowiadać wartości podanej w parametrze.
Wraz z wykorzystaniem Liquidbase jestem w stanie spisywać wszelkie zmiany jakie zachodzą w schemacie bazy danych. Na tą chwilę plik db.changelog-master.yml wygląda następująco.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
databaseChangeLog:
- changeSet:
id: create-table-animals
author: devcezz
preConditions:
- onFail: MARK_RAN
not:
tableExists:
tableName: animals
changes:
- createTable:
columns:
- column:
autoIncrement: true
constraints:
nullable: false
primaryKey: true
primaryKeyName: animal_pkey
name: id
type: BIGINT
- column:
constraints:
nullable: false
name: name
type: VARCHAR(250)
- column:
constraints:
nullable: false
name: kind
type: VARCHAR(250)
- column:
constraints:
nullable: false
name: age
type: BIGINT
tableName: animals
- changeSet:
id: add-date-tables-to-animals
author: devcezz
preConditions:
- onFail: MARK_RAN
tableExists:
tableName: animals
changes:
- addColumn:
tableName: animals
columns:
- column:
constraints:
nullable: false
name: admittedAt
type: DATETIME
defaultValueDate: CURRENT_TIMESTAMP
- column:
name: adoptedAt
type: DATETIME
Zdecydowałem się na pisanie w YAML a nie XML, ponieważ chciałem spróbować czegoś z czym jestem mniej obeznany. Dodałem też dwa changesety, aby sprawdzić jakie mechanizmy można wykorzystywać w Liquidbase. W pracy też wykorzystujemy tą bibliotekę, jednak w wersji XML oraz nie miałem okazji uczestniczyć w dodawaniu tego narzędzia. Wydaje mi się, że warto się zapoznać z tym rozwiązaniem, ponieważ mamy spisaną całą historię zmian bazy danych. Wiemy przez to jakie decyzje były podejmowane podczas dewelopmentu.
Struktura projektu
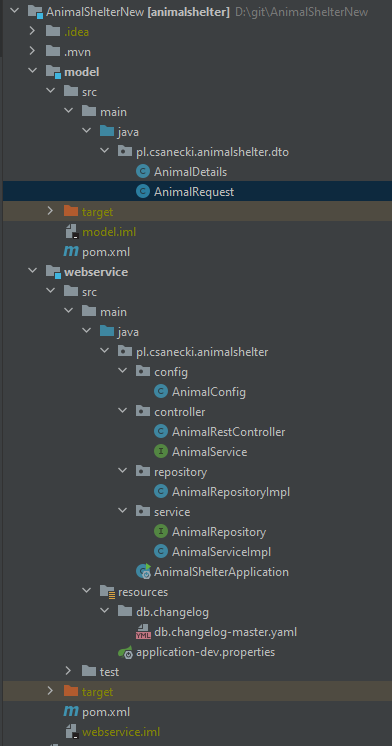
Odświeżona struktura projektu AnimalShelter
Postanowiłem podzielić aplikację na dwa moduły Mavena. Pierwszy z nich będzie zawierał tylko logikę biznesową, która będzie wolna od jakichkolwiek frameworków. Drugi natomiast będzie oparty o infrastrukturę Springa i będzie wykorzystywał funkcjonalności dostarczone przez ten pierwszy moduł. Jak na razie nie udało mi się tego jeszcze tak rozdzielić, ale jestem na dobrej drodze.
Dodatkowo widać w np. w pakiecie pl.csanecki.animalshelter.service znajduje się implementacja serwisu oraz niezbędny dla niej interfejs repozytorium. Wyszedłem z założenia, że w ten sposób AnimalShelterImpl nie jest uzależniona od żadnej konkretnej klasy. Ona tylko komunikuje jakiej zależności potrzebuje i to my jesteśmy zobligowani do jej zapewnienia.
Oczywiście zapomniałem dodać, że zdecydowałem się na najpowszechniejszą architekturę, czyli MVC. Składają się na nią poprzeczne warstwy, gdzie będziemy mieli kontrolery, logikę biznesową, persystencję oraz bazę danych.
Aktualne działanie aplikacji
Aktualnie wysyłając zapytanie POST na localhost:8080/animals z podanym niżej body.
1
2
3
4
5
{
"name": "Płotka",
"kind": "Mysz",
"age": 1
}
Uzyskamy odpowiedź 201 z zawartością.
1
2
3
4
5
6
7
8
{
"id": 3,
"name": "Płotka",
"kind": "Mysz",
"age": 1,
"admittedAt": "2020-12-05 15:02:47",
"adoptedAt": null
}
Uderzając zapytaniem GET na ten sam adres localhost:8080/animals uzyskamy listę wszystkich zwierzaków w schronisku ze statusem 200.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
[
{
"id": 1,
"name": "Karmel",
"kind": "Pies",
"age": 3,
"admittedAt": "2020-12-05 15:02:14",
"adoptedAt": null
},
{
"id": 2,
"name": "Judy",
"kind": "Kot",
"age": 2,
"admittedAt": "2020-12-05 15:02:36",
"adoptedAt": null
},
{
"id": 3,
"name": "Płotka",
"kind": "Mysz",
"age": 1,
"admittedAt": "2020-12-05 15:02:47",
"adoptedAt": null
}
]
Jeśli chcemy uzyskać dane wybranego zwierzaka musimy także wywołać GET tylko już na adres localhost:8080/animals/{id} podając w ścieżce ID konkretnego pupila. Gdy podamy ID, którego nie ma w bazie to uzyskamy status 404, natomiast, gdy dany zwierzak istnieje w systemie dostaniemy 200 wraz z ciałem odpowiedzi.
1
2
3
4
5
6
7
8
{
"id": 2,
"name": "Judy",
"kind": "Kot",
"age": 2,
"admittedAt": "2020-12-05 15:02:36",
"adoptedAt": null
}
Podsumowanie
To na razie tyle ile udało mi się uzyskać na ten moment. Będę dalej rozwijał aplikację w pierwszej kolejności zajmując się dokończeniem wszystkich endpointów oraz starając się dokonać lepszej segregacji klas. Dziękuję bardzo za to, że ze mną jesteś i będę wdzięczny jeśli podzielisz się komentarzem z opinią co sądzisz o tej serii.
Oczywiście załączam też link do mojego repozytorium z aktualnym projektem: AnimalShelterNew.