Idea Property Based Testing na pewno jest dobrze znana programistom Haskella, którzy korzystają z frameworka QuickCheck. Ja sam spotkałem się z nią niedawno i muszę przyznać, że zmieniła mój sposób patrzenia na pisanie testów. Początkowo wydawało mi się, że to nic innego jak narzędzie, które generuje nam dużą ilość danych testowych, aby zweryfikować czy nie przegapiliśmy jakiegoś istotnego warunku w naszym kodzie. Było to za sprawą zapoznania się z niezbyt jasnymi artykułami znalezionymi w Internecie. Dopiero, gdy przeczytałem wpis Johannesa Linka dowiedziałem się co tak naprawdę kryje się za pojęciem testowania opartego o właściwości. I właśnie tymi spostrzeżeniami chciałbym się z Wami podzielić.
Podejście old school
Testy pisze się najłatwiej w oparciu o pozytywną ścieżkę. W sekcji given zestawiamy niezbędne dane wejściowe, następnie w when wywołujemy kod, który chcemy zweryfikować, aby w części then sprawdzić czy rezultat ma oczekiwane wartości. Przedstawiony scenariusz znajduje odzwierciedlenie w poniższym kodzie.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Test
public void should_properly_count_words() {
//given
List<String> words = List.of(
"Pineapple",
"Banana",
"pipe",
"bAr",
"Trousers",
"PEN"
);
//and
WordCounter wordCounter = WordCounter.empty();
//when
words.forEach(wordCounter::add);
//then
assertEquals(2, wordCounter.countWordsStartingWith('B'));
assertEquals(3, wordCounter.countWordsStartingWith('P'));
assertEquals(1, wordCounter.countWordsStartingWith('t'));
assertEquals(0, wordCounter.countWordsStartingWith('a'));
}
Na początku definiujemy wyrazy, które chcemy zliczyć na podstawie ich pierwszej litery niezależnie od tego czy jest ona mała lub wielka. W kolejnym kroku wkładamy je do naszego obiektu kalkulującego, aby na koniec sprawdzić czy ilość słów faktycznie się zgadza.
Jednak czy dobrze czujemy się z tak przygotowanym testem? Może warto byłoby sprawdzić przypadki brzegowe z pustą listą czy też kolekcją o ogromnej liczbie elementów? Osobiście taki test jeszcze nie zapewniłby mnie w 100%, że wszystko działa prawidłowo. Jednak wymagania gonią i nie ma czasu, aby dopisywać kolejne skrajne przypadki. Dodatkowo więcej metod testowych sprawiłyby, że mielibyśmy więcej kodu do utrzymania. Co w takim przypadku zrobić?
Zmiana myślenia na właściwości
Jeśli przystaniemy na chwilę się i zastanowimy nad tym to możemy wysnuć następujące wnioski. Nasz kod musi spełnić kilka wymagań, które możemy przedstawić właśnie w postaci właściwości w myśl idei Property Based Testing. Dla kodu powyżej są to m.in.:
- pierwsze litery wyrazów jakie dodamy do licznika się w nim pojawią
- i odwrotnie, pierwsze litery wyrazów jakich nie dodamy do licznika się w nim nie pojawią
- w przypadku, gdy dorzucimy słowa zaczynające się na tą samą literę, niezależnie od ich wielkości, to licznik dla takiej litery zwiększy się
- kolejność wkładanych słów nie ma wpływu na licznik
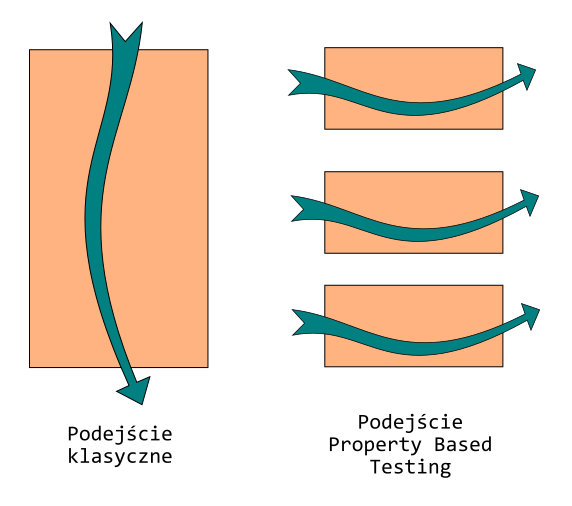
Różnica w podejściu klasycznym a Property Based Testing
Trzeba się teraz zastanowić jak ten zestaw właściwości właściwie sprawdzić. Podejście Property Based Testing nie jest zależne od żadnego rozwiązania tak samo jak np. Behaviour Driven Development. Testy możemy napisać w dowolnym narzędziu takim jak JUnit, Spock czy też TestNG. Oczywiście jednak lepiej wykorzystać specjalizowaną w tym temacie bibliotekę jaką jest np. jqwik (opartą o silnik JUnita).
Testujemy właściwość po raz pierwszy
Na tapet jako pierwszy weźmy przypadek z pojawianiem się pierwszych liter wyrazów w liczniku, gdy je do niego dodamy. Z testu przedstawionego wyżej wychodzi na to, że gdy uwzględnimy dane słowo w naszym obiekcie to zwracana wartość dla jego pierwszej litery z metody countWordsStartingWith powinna być większa od zera. Wykorzystując jqwik do naszego przypadku mogłoby to wyglądać następująco.
1
2
3
4
5
6
7
8
@Property
public boolean allFirstLettersForAddedWordsShowUpInCounter(
@ForAll List<@AlphaChars @StringLength(min = 1) String> words) {
WordCounter wordCounter = WordCounter.empty();
words.forEach(wordCounter::add);
return words.stream()
.allMatch(word -> 0 < wordCounter.countWordsStartingWith(word.charAt(0)));
}
Akurat przypadek z literałami nie jest najszczęśliwszy, ponieważ musimy wprowadzić kilka ograniczeń dla przekazywanych wyrazów. Chcemy, żeby składały się one z samych liter i były długości co najmniej jednego znaku. Możemy dokonać tego poprzez adnotacje @AlphaChars oraz @StringLength, które umieszczamy przy typie generycznym listy, czyli w naszym przypadku jest to klasa String. Jeśli uruchomimy tak zdefiniowany test dostaniemy następująca zwrotkę.
timestamp = 2022-04-29T17:09:08.729107300, WordTestPBT:allFirstLettersForAddedWordsShowUpInCounter =
|--------------------jqwik--------------------
tries = 1000 | # of calls to property
checks = 1000 | # of not rejected calls
generation = RANDOMIZED | parameters are randomly generated
after-failure = PREVIOUS_SEED | use the previous seed
when-fixed-seed = ALLOW | fixing the random seed is allowed
edge-cases#mode = MIXIN | edge cases are mixed in
edge-cases#total = 5 | # of all combined edge cases
edge-cases#tried = 5 | # of edge cases tried in current run
seed = 8181786222562711739 | random seed to reproduce generated values
W tym zaprezentowanym sporym natłoku informacji znajdziemy m.in. liczbę prób wywołania naszego testu (tries), liczbę faktycznie wywołanych sprawdzeń testu (checks), sposób generowania parametrów (generation), “ziarno” losowości (seed) czy też strategię jaka zostanie wykorzystana, gdy test nie przejdzie (after-failure). Oczywiście są to dane pochodzące z jqwik, którym nie chciałbym się zajmować w ramach tego wpisu. Być może poruszę jego kwestię w jednym z następnych artykułów.
Spróbujmy zweryfikować kolejną właściwość
Mam nadzieję, że pierwszy przypadek dał już Ci jakiś pogląd w jaki sposób przestawić swoje myślenie w ramach Property Based Testing. Jednak dla treningu spróbujmy sprawdzić kolejną właściwość. Będzie, więc to: “pierwsze litery wyrazów jakich nie dodamy do licznika się w nim nie pojawią”. No to siup!
1
2
3
4
5
6
7
@Property
public boolean allFirstLettersForWordsThatAreNotAddedDoesNotShowUpInCounter(
@ForAll List<@AlphaChars @StringLength(min = 1) String> words) {
WordCounter wordCounter = WordCounter.empty();
return words.stream()
.allMatch(word -> 0 == wordCounter.countWordsStartingWith(word.charAt(0)));
}
Ten test wydaje się naprawdę banalny. Jeśli nic nie dodamy do naszego licznika to żadna pierwsza litera z podanych słów nie powinna się w nim odłożyć. To też właśnie weryfikujemy przez porównanie rezultatu metody countWordsStartingWith z zerem. Idźmy zatem dalej z zmierzmy się z kolejną właściwością. Tutaj sprawa już nie wydaje się być taka prosta, lecz postaramy się to wymaganie zapisać w jak najprostszy sposób. Jest to w sumie podejście, które testowaliśmy na samym początku, ale na większą skalę przekazywanych danych.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Property
public boolean counterSumsUpOccurrencesOfFirstLettersOfAddedWordsStaringWithTheSameLetter(
@ForAll List<@AlphaChars @StringLength(min = 1) String> words) {
WordCounter wordCounter = WordCounter.empty();
words.forEach(wordCounter::add);
return words.stream()
.allMatch(word -> sumWordsWithTheSameFirstLetterAs(word, words) == wordCounter.countWordsStartingWith(word.charAt(0)));
}
private long sumWordsWithTheSameFirstLetterAs(String word, List<String> words) {
return words.stream()
.map(passedWord -> passedWord.toUpperCase().charAt(0))
.filter(firstLetter -> firstLetter.equals(word.toUpperCase().charAt(0)))
.count();
}
Jak widać musieliśmy sami zdefiniować dodatkową metodę, która zliczy nam specyficzne przypadki. Przyznam, że jest tutaj zbyt dużo logiki odpowiedzialnej za zliczenie odpowiedniej ilości wyrazów. Może można zrobić to lepiej?
Próba lepszego rozwiązania
Lepiej oddelegować tworzenie prawidłowych słów do specjalizowanego providera. W naszym przypadku będzie to metoda wordsWithTheSameFirstLetter, która losuje pierwszą literę, a później dokleja do niej resztę słowa. W związku z tym, że chcemy przebadać właściwość polegającą na zweryfikowaniu ilość odłożonych słów na daną literę to instruujemy bibliotekę, żeby stworzona lista zawierała zawsze chociaż jeden element.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Property
public boolean counterSumsUpOccurrencesOfFirstLettersOfAddedWordsStaringWithTheSameLetter(
@ForAll("wordsWithTheSameFirstLetter") List<String> words) {
WordCounter wordCounter = WordCounter.empty();
words.forEach(wordCounter::add);
return words.stream()
.findFirst()
.map(word -> words.size() == wordCounter.countWordsStartingWith(word.charAt(0)))
.orElse(false);
}
@Provide
Arbitrary<List<String>> wordsWithTheSameFirstLetter() {
return Arbitraries.chars()
.alpha()
.flatMap(firstLetter -> Arbitraries.strings()
.alpha()
.map(restOfWord -> firstLetter + restOfWord)
.list()
.ofMinSize(1));
}
Test działa prawidłowo, tylko jest jedno ‘ale’. Jeśli przyjrzymy się wygenerowanym słowom to zauważymy, że co prawda zaczynają się na tą samą literę, ale jest ona zawsze tej samej wielkości np. [BDfozCyHNM, BviabYbaSODXmgAlIItmoRNNvXe, BxPnDCEt, BbUNsYhXQS, BVgUWnlCFy, BANluRzuD, BAluQVOgqD]. Postarajmy się to naprawić.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
@Property
public boolean counterSumsUpOccurrencesOfFirstLettersOfAddedWordsStaringWithTheSameLetter(
@ForAll("wordsWithTheSameFirstLetterButRandomCase") List<String> words) {
WordCounter wordCounter = WordCounter.empty();
words.forEach(wordCounter::add);
return words.stream()
.findFirst()
.map(word -> words.size() == wordCounter.countWordsStartingWith(word.charAt(0)))
.orElse(false);
}
@Provide
Arbitrary<List<String>> wordsWithTheSameFirstLetterButRandomCase(
@ForAll("wordsWithTheSameFirstLetter") List<Tuple.Tuple2<Character, String>> wordsParts) {
return Arbitraries.randoms()
.map(random -> wordsParts.stream()
.map(wordParts -> {
char firstLetter = random.nextBoolean() ?
Character.toUpperCase(wordParts.get1()) :
Character.toLowerCase(wordParts.get1());
return firstLetter + wordParts.get2();
})
.toList());
}
@Provide
Arbitrary<List<Tuple.Tuple2<Character, String>>> wordsWithTheSameFirstLetter() {
return Arbitraries.chars()
.alpha()
.flatMap(firstLetter -> Arbitraries.strings()
.alpha()
.map(restOfWord -> Tuple.of(firstLetter, restOfWord))
.list()
.ofMinSize(1));
}
Zaproponowane rozwiązanie dostarcza jeszcze jeden provider, który wykorzystuje ten wcześniejszy. W ten sposób włączamy element losowości jeśli chodzi o wielkość pierwszej litery. Dzięki takiemu podejściu możemy otrzymać np. następującą listę [TNpKOMazxIXqsbY, TA, tsNhbtOiDnlqkrTsrIDjHGeddOSsU, TilJfgDejouMadmLZoQSsmAIan].
Trzeba przyznać, że API dostarczone przez jqwik naprawdę jest czytelne i nawet bez znajomości tego narzędzia można domyślić się o co dokładnie chodzi w kodzie. Zastanawiam się tylko czy powyższe rozwiązanie jest najlepsze. Jeśli miałbyś lub miałabyś lepszy pomysł na zweryfikowanie tej właściwości to daj znać w komentarzu.
Podsumowanie
Mam nadzieję, że ten krótki artykuł wyjaśnił co nie co ideę stojącą za Property Based Testing. Nie chciałem w nim się skupiać na technikaliach danej biblioteki, a raczej wyjaśnić w kilku słowach samo sedno tego podejścia do pisania testów. Oczywiście trudniej byłoby to osiągnąć bez użycia składni wybranego narzędzia, które w znacznym stopniu upraszcza kod.
Na pewno na początku nauki Property Based Testing trzeba będzie poświęcić sporo czasu, aby przestawić swoje myślenie w kwestii weryfikowania w ten sposób funkcji biznesowych. Jednak wydaje mi się, że dzięki zastosowaniu Property Based Testing w niektórych miejscach kodu będziemy mogli spać spokojniej. Trzeba jednak uważać na czas wykonania takich testów. Może warto będzie je puszczać raz na dobę. Czas wykonania testu opartego o podejście klasyczne zajmował kilkadziesiąt milisekund. Natomiast trzy testy właściwości z racji generowania danych trwały kilka sekund. Widać, więc różnicę kilku rzędów wielkości. Wychodzi na to, że jak zawsze wszystko ma dwie strony medalu.
Link do projektu na GitHub: https://github.com/cezarysanecki/code-from-blog