Architektura reaktywna jest niczym innym jak systemem (najczęściej rozproszonym) opartym na komunikacji pomiędzy niezależnymi usługami za pomocą asynchronicznych komunikatów. Powstała w głównej mierze w oparciu o The Reactive Manifesto (responsive, resilient, elastic, message driven). Ciężko jednak powiedzieć w jaki sposób zaimplementować architekturę reaktywną, ponieważ nie ma określonych wytycznych co do jej realizacji. Z tego powodu skupię się w dzisiejszym wpisie na wersji opartej o zdarzenia. Warto na początku więc ujednolicić terminy, które są obecne w tej architekturze.
Podstawową jednostką jest komunikat (message), czyli forma danych przesyłana pomiędzy usługami. Jej odpowiedzialnością jest przenoszenie zawartości komendy lub zdarzenia. Jednak, aby wysyłać komunikaty musi zostać zapewniona odpowiednia infrastruktura w postaci systemu kolejek jakim jest np. Kafka czy RabbitMQ. Komendą (commend) natomiast jest żądanie wysyłane do wybranej usługi, aby wywołać jej określone działanie. Warto dodać, że odbiorcą komendy jest tylko jeden wybrany adresat. Zdarzenie (event) to informacja o tym co właśnie wydarzyło się w systemie. Nadawca ogłasza wszystkim usługom informację o zaistniałej sytuacji poprzez system kolejkowy.
Jak wygląda architektura reaktywna?
Na początku warto dodać sprostowanie. Często zamiennie, ale niestety mylnie, używa się są ze sobą dwóch terminów: “programowanie reaktywne” i “architektura reaktywna”. Pierwsza opcja porusza się w zagadnieniach niskopoziomowych takich jak języki programowania czy biblioteki pozwalające na asynchroniczne wywoływanie metod (np. WebFlux). Drugie pojęcie dotyczy wysokopoziomowego spojrzenia na system i to na nim będę się teraz skupiał.
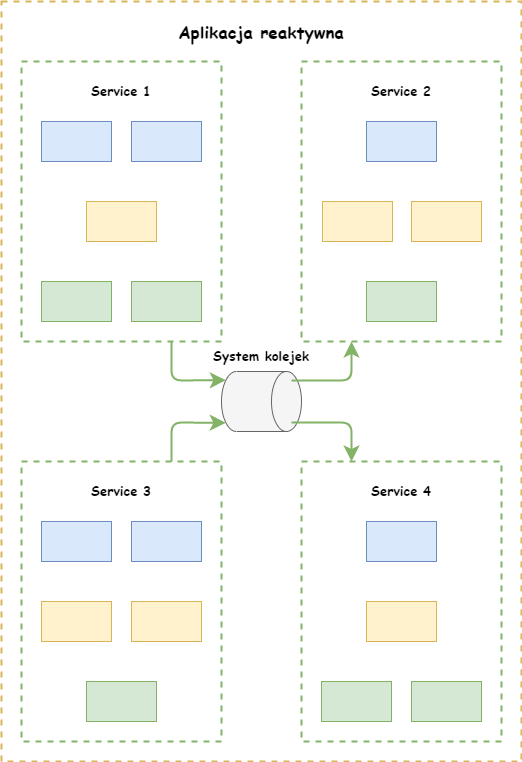
Schemat architektury reaktywnej
Architektura reaktywna jest bardzo podobna do mikroserwisów za wyjątkiem tego, że odrzuca ona komunikację poprzez bezpośrednie wywołania usług. Stawia mocno na asynchroniczność, gdzie wygenerowana wiadomość przez nadawcę nie musi być natychmiast skonsumowana przez odbiorcę. To właśnie sprawia, że aplikacje posiadają luźne połączone ze sobą. Oczywiście daje to możliwość niezależnego skalowania usług czy też rozwijania ich albo wdrażania. Nie mniej jednak powstają inne problemy do rozwiązania, które powoduje m.in. asynchroniczna komunikacja. Z tego powodu należy wziąć pod uwagę następujące aspekty: obsługę sytuacji wyjątkowych, rozproszoną transakcyjność, zachowanie kolejności obsługi komunikatów, przypadkowe wysłanie tej samej wiadomości.
Za i przeciw
Niezależne usługi składające się na architekturę reaktywną mogą być niemal bez ograniczeń skalowalne. Nie można także narzekać na brak narzędzi do tworzenia tego typu systemów. Istnieją systemy kolejkowe (w tym opensource’owe) takie jak np. wcześniej wspomniane RabbitMQ i Kafka czy ActiveMQ, które bez problemu można wykorzystać do asynchronicznej komunikacji. Warto dodać, że powstały także takie biblioteki jak Netty, Orleans, Akka pomagające w tworzeniu reaktywnych systemów.
Tam gdzie powstają systemy rozproszone, zespoły z wysokimi kompetencjami muszą wkroczyć do akcji. Wymaga się od nich, aby wiedzieli w jaki sposób np. zaimplementować asynchroniczną komunikację pomiędzy usługami. Bez cienia wątpliwości globalny poziom systemu jest bardzo złożony, więc nie powinno się stosować architektury reaktywnej w aplikacjach, gdzie kluczowym wymaganiem nie jest skalowalność. Jest to po prostu przerost formy nad treścią.
Podsumowanie
Muszę przyznać, że architektura reaktywna wygląda naprawdę ciekawie, jednak na pewno trzeba mieć dobre powody, aby ją wdrożyć. Sam na ten moment nie mam pomysłu w jakiej dziedzinie można by zastosować taki system. Mam nadzieję, że w mojej karierze będzie mi dane zobaczyć chociaż jedną aplikację, która będzie rozwijana właśnie w tej architekturze. Na ten moment to tyle, w ostatnim już artykule w tej serii chciałbym bliżej przyjrzeć się architekturze serverless!