Spock według mnie jest naprawdę dobrą alternatywą dla JUnit oraz TestNG. Wyróżnia go fakt, że jest to testowy framework oparty o język Groovy. Dzięki temu może on wykorzystywać jego wyraziste konstrukcje językowe do pisaniu testów jak np. nazwy metod w cudzysłowach czy podwójny znak mniejszości ‘«’, aby dodać elementy do kolekcji. Jednak pomimo tak wielu korzyści zawsze znajdzie się coś na co można trochę ponarzekać. W przypadku tego artykułu jest to połączenie Spocka z IntelliJ. Czasem ta para ze sobą nie współgra tak jakby można było się tego spodziewać.
TIP: Można ustawić wcięcia dla linii kodu pod etykietami w Groovy. W tym celu należy zmienić następującą opcję w Intellij: “Editor -> Code Style -> Groovy -> Tabs and Indents -> Label indent: 4”.
Open Source at Exception
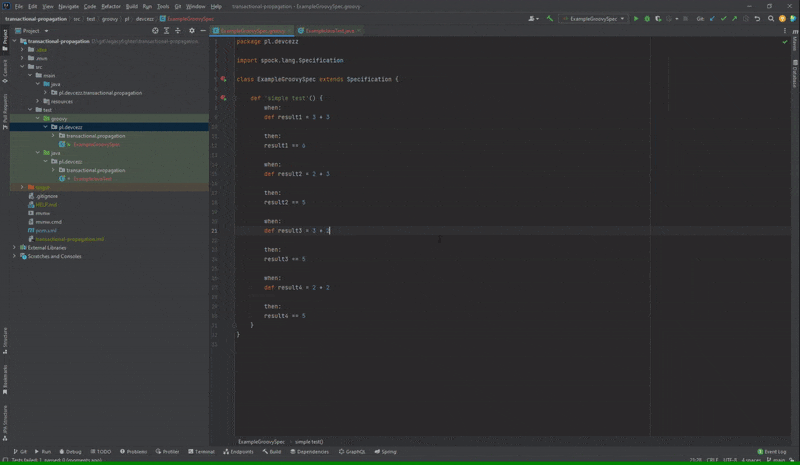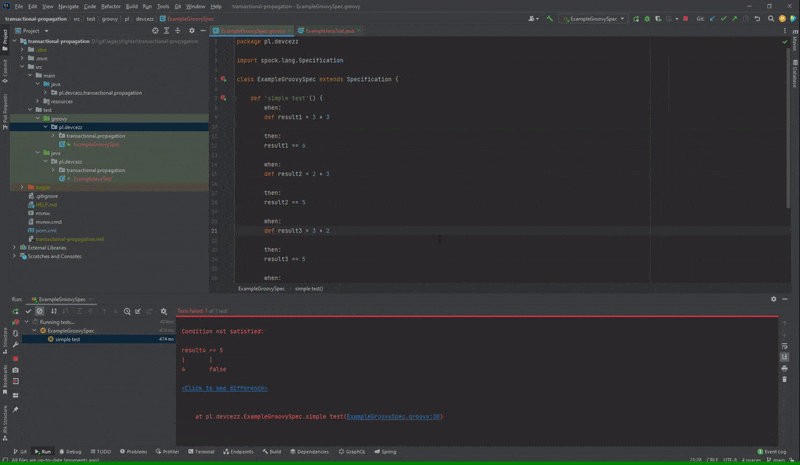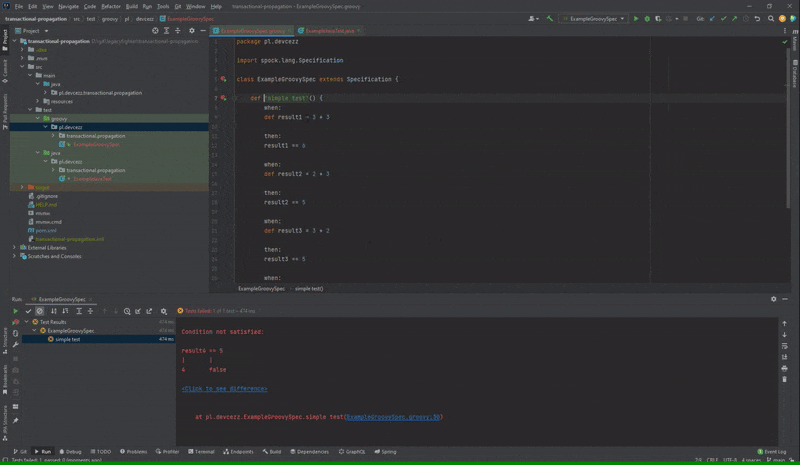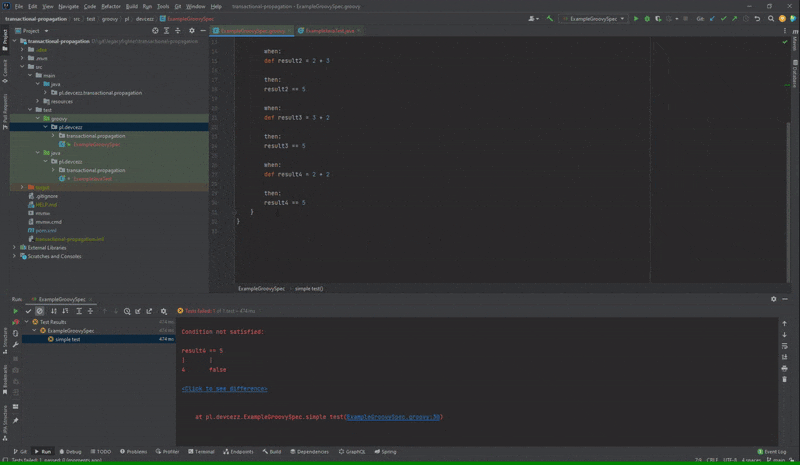
Pierwszym przypadkiem jest niedziałająca opcja “Open Source at Exception”, której zadaniem jest przeniesienie nas w kodzie testu do miejsca, gdzie nie przeszła asercja. Dla JUnit działa to jak należy, natomiast w Spock już niekoniecznie. Ta opcja wydaje się być po prostu wygodna w przypadku, gdy kod danej metody testowej znacznie się rozrośnie i będzie posiadał sporo asercji.
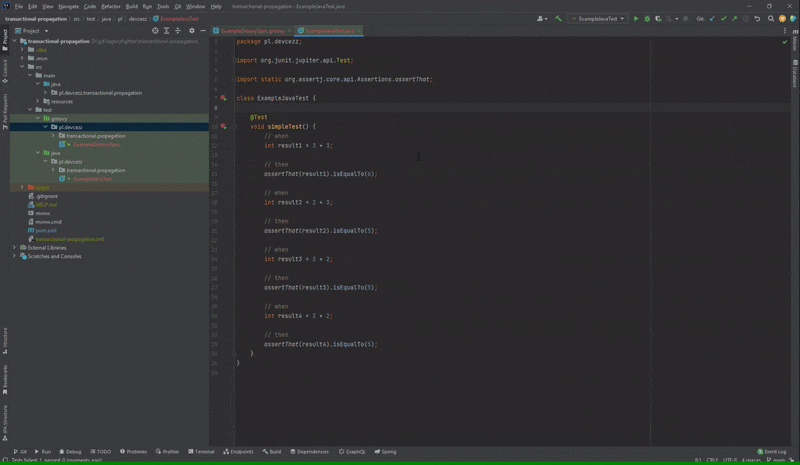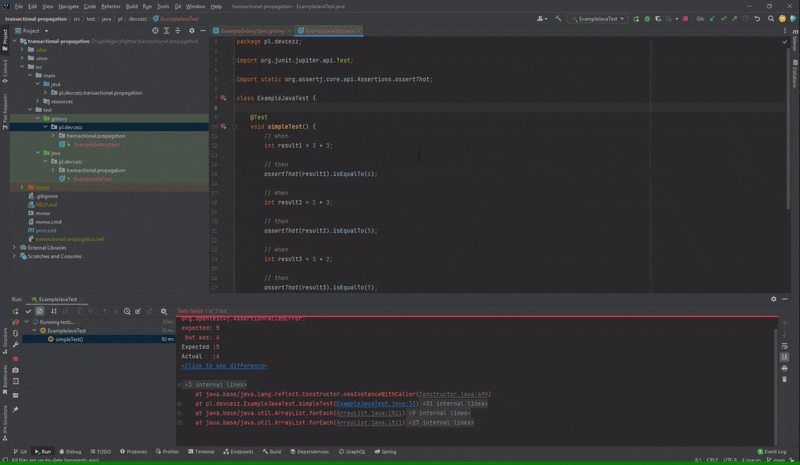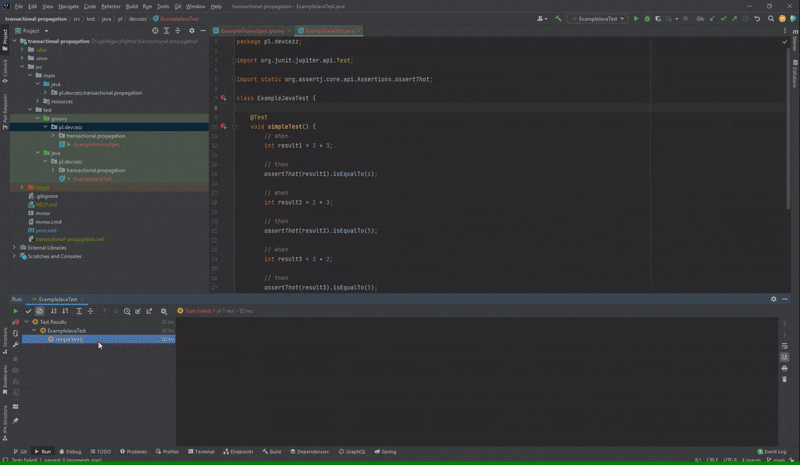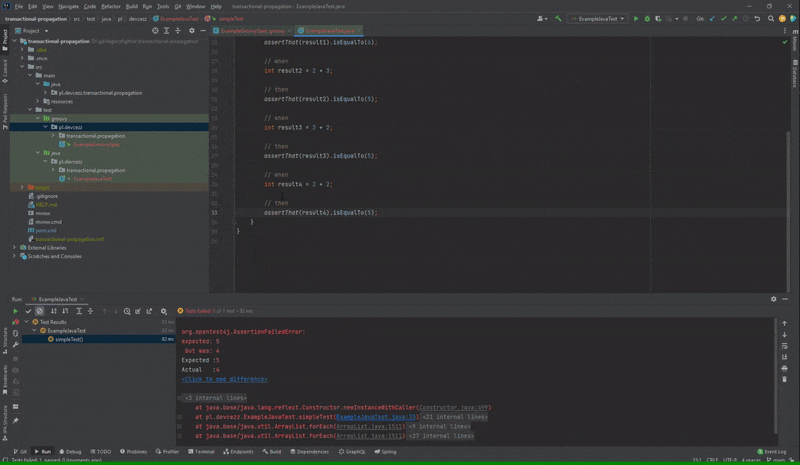
Poprawnie działająca opcja “Open Source at Exception” dla JUnit
Nieprawidłowo działająca opcja “Open Source at Exception” dla Spock
Po podwójnym kliknięciu na test, który nie przeszedł w przypadku JUnit zostaniemy przeniesieni do błędnej asercji. Natomiast w Spock kursor nakieruje się na nazwę metody testowej. Na platformie YouTrack od JetBrains może sprawdzić, że istnieje już taki błąd od roku.
Brak wsparcia formatowania dla podzielonej tabeli danych
Czasami wiele parametrów jest od siebie zależnych i nie chcielibyśmy pisać wielu metod testowych o takim samym ciele. Z tego powodu stosujemy testy parametryzowane i muszę przyznać, że w Spock ich implementacja jest naprawdę wygodna. Piszemy po prostu sekcję where w ramach tej samej metody i podajemy tabelę danych rozdzielając je przez ‘|’ lub ‘;’. Czasami jednak tych kolumn jest tak dużo, że chcielibyśmy ją podzielić. Oczywiście jest to jak najbardziej możliwe, ale gorzej już z automatycznym formatowaniem takiej tabeli.
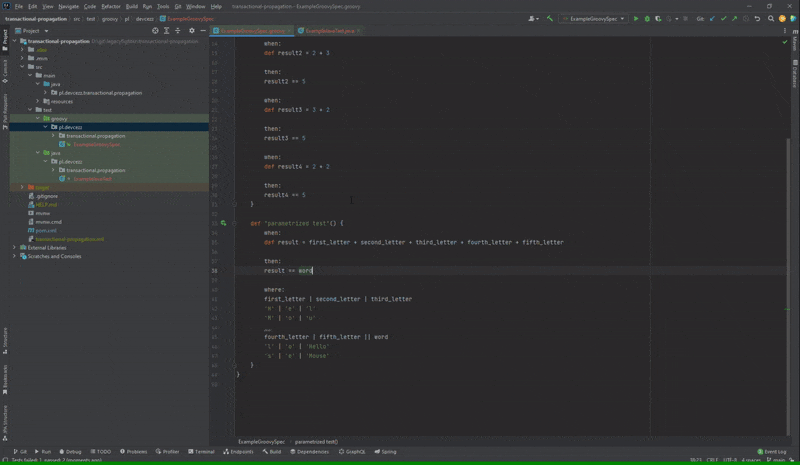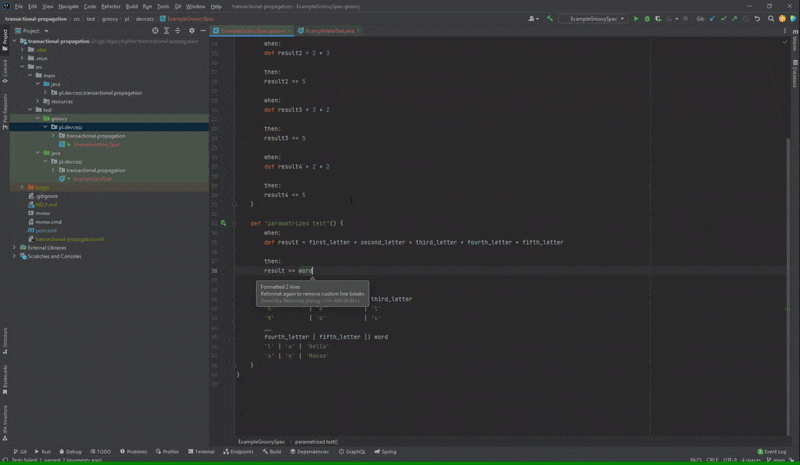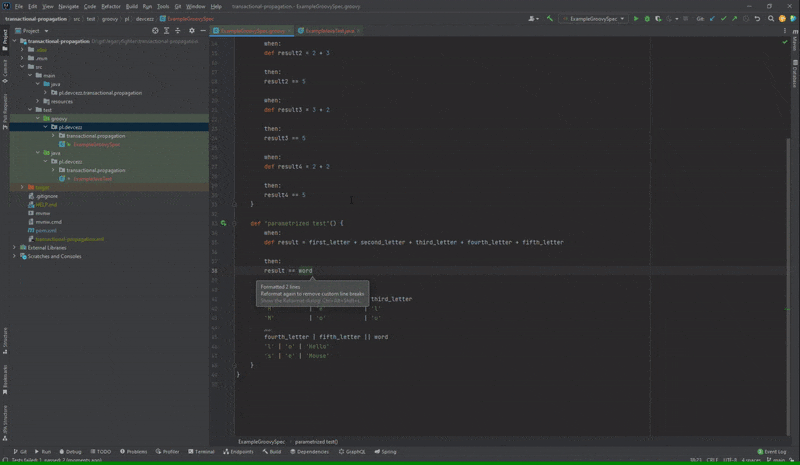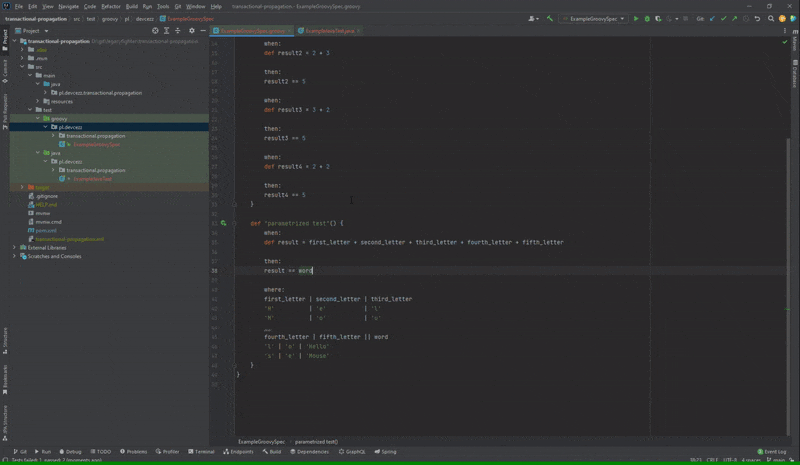
Brak formatowania podzielonej tabeli danych parametryzowanego testu
Po naciśnięciu kombinacji Ctrl+Alt+L jak można zauważyć druga część tabeli pozostała nienaruszona. Ten błąd jest na pewno irytujący, ponieważ czasami trzeba formatować ręcznie sporą ilość kodu. Oczywiście go również znajdziemy na YouTrack, powstał on 2 miesiące temu.
Dla mnie osobiście powinno się robić jeszcze formatowanie w taki sposób, aby wszystkie linijki pod słowami takimi jak given, when, then, where itd. wyszły o jeden tabulator dalej. W ten sposób każda z sekcji byłaby widoczna na pierwszy rzut oka. Próbowałem z tym walczyć, ale przy każdym formatowaniu automatycznym moja praca szła na marne. To jest tylko jednak moje osobiste odczucie i nie utrudnia pracy.
Zmiana nazwy zmiennej a literał w @Unroll
Po napisaniu kawałka kodu praktycznie w 100% wiemy, że dane nazwy zmiennych się zmienią. Nie inaczej ma się to w przypadku kodu metod testowych. W Spock istnieje adnotacja @Unroll, której zadaniem jest uznanie każdego przypadku z parametryzowanego testu jako osobnego testu. Ma to głównie znaczenie przy tworzeniu raportu. Łącząc te dwa zagadnienia dostaniemy problem przedstawiony na poniższej grafice.

Problem ze zmianą nazwy zmiennej a nazwą metody testowej
Obydwa sposoby użycia @Unroll są prawidłowe. Jednak w przypadku wykorzystania adnotacji bez literału oraz użycia nazw zmiennych w nazwie metody, gdy zrefaktoryzujemy je w kodzie to nie ulegną one zmianie. Natomiast przy zwykłej nazwie metody, a parametryzacji nazwy metody w @Unroll wszystko zadziała prawidłowo. Ten błąd również znajduje się na w sferze problemów od 9 lat z aktualizacją sprzed roku w lutym.
Podsumowanie
Wyżej wymienione błędy nie są krytyczne, ale potrafią być uciążliwe. Sam Spock to naprawdę dobry framework do testowania i stanowi świetną alternatywę dla pisania testów w samej Javie. Oczywiście są też takie uciążliwości jak brak błędu, gdy dana klasa nie ma konstruktora z wybranymi parametrami, a my chcemy go przez przypadek użyć. Dostaniemy tylko ostrzeżenie, które podświetli nam problematyczny fragment kodu na żółto, a testy i tak się uruchomią. Oczywiście ten przypadek testowy nie przejdzie i dopiero w logach dostaniemy informacje o błędzie kompilacji. Jednak ten problem to po prostu pokłosie wykorzystania skryptowego języka Groovy i ciężko winić za to Spocka. Nie zmienia to faktu, że pisanie testów w ten sposób jest utrudnione.
Oczywiście możemy również dostać się w teście do prywatnych pól danego obiektu i je nadpisywać. IntelliJ również nas poinformuje o tym poprzez wyróżnienie danego wywołania żółtą poświatą. Jednak okazuje się, że to jest poważny błąd języka Groovy samego w sobie:
Jestem ciekaw czy Ty również wykorzystujesz Spocka do testów w pracy i również napotkałeś bądź napotkałaś problemy z nim związane. Podziel się swoim doświadczeniem w komentarzu.