Przetwarzanie wsadowe to użyteczne narzędzie, które pozwala na wykonywanie serii zadań bez interakcji z użytkownikiem. Jest to alternatywa dla programów, które wymagają aktywności użytkownika końcowego, aby wprowadzał dane przez terminal albo interfejs graficzny.
Batch processing… is defined as the processing data without interaction and interruption.
Michael Minella, “Pro Spring Batch”
Właśnie ten sposób przetwarzania jest wykorzystywany przy procesowaniu transakcji bankowych (najczęściej w nocy, kiedy ruch jest najmniejszy), analizie statycznej, generowaniu raportów czy procesach ETL (Extract, Transform, Load). Przetwarzanie wsadowe jest historycznie związane z komputerami klasy Mainframe, jednak dzisiaj możemy je również zaprogramować przy wykorzystaniu Springa, a dokładniej dzięki jednemu z jego projektów - Spring Batch.
Problem do rozwiązania
Zdefiniujmy na początku jaki mamy problem do rozwiązania. Na wejściu otrzymujemy plik CSV wraz z danymi pacjentów, którzy zostali zapisani do naszej placówki medycznej. Następnie musimy zweryfikować czy każdy z interesantów ma opłacone ubezpieczenie. Na koniec zapiszemy przetworzone dane do bazy danych. Poniżej zamieściłem przykładowe imiona i nazwiska wraz z wymyślonym identyfikatorem osobistym. Użyłem w tym celu generatora imion oraz generatora id.
334080,Jesse,Richards
846884,Erin,Stewart
702588,Glen,Stone
638872,Bret,Young
742506,Bev,Richards
412592,Fran,Walsh
557143,Sidney,King
375846,Terry,Owen
847630,Erin,Kelly
870814,Gabby,Walsh
600996,Ashley,Khan
479311,Frankie,Kaur
726659,Gale,Miller
640314,Brice,Simpson
371910,Skylar,Macdonald
188741,Skye,Harvey
778174,Franky,Parry
198717,Jordan,Fox
894628,Angel,Richardson
276626,Jess,Harrison
Wykorzystanie Spring Batch
Jak zawsze zaczynamy od stworzenia projektu za pomocą strony start.spring.io. Ja do swoich celów użyłem Mavena, Javy 16, pakowania do JAR oraz zależności w postaci właśnie Spring Batch. Dodatkowo dodałem jeszcze MySQL, aby móc zapisać wynik pracy w tej właśnie bazie danych.
Najważniejszym fragmentem pliku pom.xml jest miejsce, w którym deklarujemy, że chcemy mieć zależność do niezbędnego nam projektu Spring Batch.
1
2
3
4
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
Teraz jesteśmy gotowi, aby zacząć pisać kod.
Big picture
Spring Batch dostarcza nam całą architekturę procesowania wsadowego, abyśmy mogli przy jego wykorzystaniu zaimplementować tylko naszą logikę biznesową. Nie musimy się przez to martwić infrastrukturą rozwiązania. Dostajemy wydajny szkielet aplikacji, który umożliwia nam przetwarzanie dużej liczby rekordów, zarządzanie transakcjami, tworzenie statystyk wyników pracy przetwarzania wsadowego oraz administrowanie zasobami. Poniżej zamieściłem schemat działania Spring Batch znaleziony na stronie No Fluff Jobs.
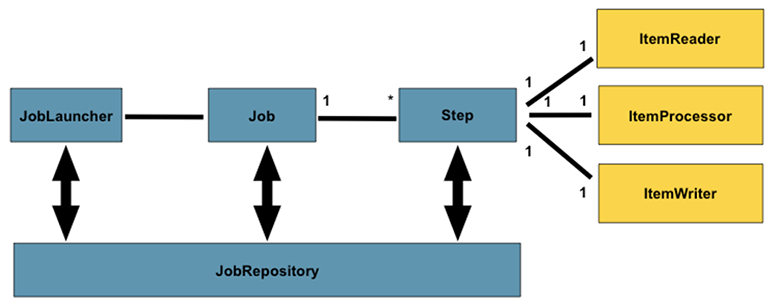
Schemat architektury projektu Spring Batch, źródło: https://nofluffjobs.com/blog/przetwarzanie-batch-owe-w-springu
Sprawdzimy jakie zadanie ma każdy z tych elementów:
JobLauncher– zarządza utworzonymi JobamiJobRepository– gromadzi dane o JobachJob– przechowuje całokształt pracy do wykonania, składa się z krokówStep– wykonuje postawione przed nim zadanie, jest elementem składowym JobaItemReader– wczytuje dane z zewnętrznego źródła i przygotowuje je do przetworzenia przez procesorItemProcessor– przetwarza uzyskane daneItemWriter– zapisuje przetworzone dane
W naszym przypadku musimy utworzyć jednego Joba, który zawiera jeden krok. Ten natomiast będzie miał jednostki odpowiedzialne za wczytanie danych, procesowanie ich i zapis.
Implementacja
Korzystając z okazji programowania w Javie 16 stworzyłem dwa rekordy przedstawiające kolejno wiersz pliku CSV oraz dane zapisywane w bazie danych MySQL.
1
2
3
4
5
6
7
8
9
10
11
12
13
public record PatientRow(
Integer personalNumber,
String firstName,
String lastName
) {}
public record Patient(
Integer personalNumber,
String firstName,
String lastName,
boolean insured,
LocalDate registered
) {}
Przejdźmy teraz do klasy konfiguracyjnej. Musimy wstrzyknąć do niej dwie fabryki odpowiedzialne za tworzenie Jobów oraz ich kroków. Robimy to przez zastosowanie adnotacji @Autowired na polach JobBuilderFactory oraz StepBuilderFactory. Dodatkowo, aby nie martwić się bardziej rozbudowaną konfiguracją należy użyć adnotację @EnableBatchProcessing, która udostępnia nam niezbędne funkcje do ustawienia naszego przetwarzania wsadowego.
1
2
3
4
5
6
7
8
9
10
11
12
@Configuration(proxyBeanMethods = false)
@EnableBatchProcessing
class BatchConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
// ...
}
Sposób wczytywania danych
Następnym krokiem jest utworzenie beana odpowiedzialnego za wczytanie danych do aplikacji z pliku. Nie ma potrzeby tworzenia żadnej dodatkowej klasy, wystarczy skorzystać z FlatFileItemReader<T> implementującej pośrednio interfejs ItemReader<T>. Dzięki przyjaznemu API jesteśmy w stanie odczytać zawartość pliku przy pomocy przekazywanych parametrów do buildera.
1
2
3
4
5
6
7
8
9
10
@Bean
FlatFileItemReader<PatientRow> reader() {
return new FlatFileItemReaderBuilder<PatientRow>()
.name("patientItemReader")
.resource(new ClassPathResource("2021_07_19_patients.csv"))
.delimited()
.names("personalNumber", "firstName", "lastName")
.fieldSetMapper(new RecordFieldSetMapper<>(PatientRow.class))
.build();
}
Nadajemy nazwę dla naszego ItemReader<T>, następnie wskazujemy źródło danych. Używamy metody delimited, aby nasz wsad został podzielony na pola, które są oddzielone przecinkiem w pliku CSV. Podajemy nazwy pól w kolejności w jakiej znajdują się w zewnętrznym zbiorze danych i wieńczymy to wskazując jaką klasę chcemy zainicjalizować danymi.
Przepis na zapisanie przetworzonych danych
Na koniec naszego kroku przetwarzania musimy zadeklarować gdzie te dane chcemy zapisać. Ja wykorzystałem do tego celu bazę danych MySQL. Jednak, aby tego dokonać trzeba stworzyć odpowiedniego beana, który prezentuje się następująco.
1
2
3
4
5
6
7
8
9
10
11
12
@Bean
public JdbcBatchItemWriter<Patient> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Patient>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql(
"INSERT INTO patient " +
"(personal_number, first_name, last_name, insured, admitted_at) " +
"VALUES " +
"(:personalNumber, :firstName, :lastName, :insured, :registered)")
.dataSource(dataSource)
.build();
}
Używamy w tym celu JdbcBatchItemWriter<Patient> implementujący niezbędny interfejs ItemWriter<T>. Aby go utworzyć należy skorzystać z buildera i podać sposób w jaki zostaną dostarczone parametry do zapytania SQL, zapisać interesujące nas zapytanie oraz wstrzyknąć źródło danych.
Dodatkowe beany
1
2
3
4
5
6
7
8
9
@Bean
PatientService patientService() {
return new PatientService();
}
@Bean
PatientJobListener listener() {
return new PatientJobListener();
}
Tworzymy serwis PatientService weryfikujący czy dany pacjent jest ubezpieczony czy nie. Pominę jego dokładną implementację, ponieważ nie jest to istotne z punktu widzenia artykułu. Jednak warto zwrócić uwagę w jaki sposób został zakodowany PatientJobListener i jakie jest jego zadanie.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
class PatientJobListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(PatientJobListener.class);
@Override
public void beforeJob(final JobExecution jobExecution) {
log.info("-----> Job has started <-----");
}
@Override
public void afterJob(final JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("-----> Job has ended successfully <-----");
} else {
log.info("-----> Job has ended with error <-----");
}
}
}
Aby stworzyć listener trzeba napisać klasę rozszerzającą JobExecutionListenerSupport lub implementującą interfejs JobExecutionListener. Nie ma to najmniejszego znaczenia, ponieważ klasa JobExecutionListenerSupport również implementuje interfejs JobExecutionListener pozostawiając puste ciała metod beforeJob i afterJob. W naszym przykładzie listener został wykorzystany, aby wyświetlić w logach aplikacji, że Job rozpoczął przetwarzanie i czy zakończył się powodzeniem czy nie.
Clue przetwarzania
Najważniejszym beanem jest środkowa część przetwarzania kroku, czyli procesowanie. W naszym przypadku będzie to nowo utworzona klasa zależna od serwisu PatientService.
1
2
3
4
@Bean
PatientItemProcessor processor(PatientService patientService) {
return new PatientItemProcessor(patientService);
}
Implementacja wygląda następująco. Klasa implementuje generyczny interfejs ItemProcessor, gdzie pierwszym argumentem jest klasa podlegająca procesowaniu natomiast drugim efekt pracy procesora. Sama metoda weryfikuje czy pacjent jest ubezpieczony i następnie tworzy obiekt Patient. Przy okazji wyświetlany jest log w konsoli o tym, który pacjent jest aktualnie przetwarzany. Można powiedzieć, że ta klasa jest sercem naszego przetwarzania wsadowego.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
import java.time.LocalDate;
class PatientItemProcessor implements ItemProcessor<PatientRow, Patient> {
private static final Logger log = LoggerFactory.getLogger(PatientItemProcessor.class);
private final PatientService patientService;
PatientItemProcessor(final PatientService patientService) {
this.patientService = patientService;
}
@Override
public Patient process(final PatientRow patientRow) {
log.info("Processing patient of personal number: " + patientRow.personalNumber());
boolean insured = patientService.isPatientInsured(patientRow);
return new Patient(
patientRow.personalNumber(),
patientRow.firstName(),
patientRow.lastName(),
insured,
LocalDate.now());
}
}
Bean Joba i kroku
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Bean
public Job job(PatientJobListener listener, Step step) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step)
.end()
.build();
}
@Bean
public Step step(
FlatFileItemReader<PatientRow> reader,
PatientItemProcessor processor,
JdbcBatchItemWriter<Patient> writer
) {
return stepBuilderFactory.get("step")
.<PatientRow, Patient> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
Przy konfiguracji beana dla Joba nadajemy mu nazwę, wskazujemy w jaki sposób ma być inkrementowany id wykonania, aby łatwiej identyfikować stan wykonania Jobów w repozytorium, przekazujemy wcześniej utworzony listener i podajemy niezbędną ilość kroków. W naszym przypadku będzie to tylko jeden krok przetwarzający dane w blokach 10 wierszowych i korzystający z wyżej zdefiniowanych beanów ItemReader, ItemProcessor i ItemWriter.
Uruchomienie przetwarzania wsadowego
Oczywiście musimy utworzyć jeszcze schemat bazy danych wraz z niezbędną tabelą.
1
2
3
4
5
6
7
8
CREATE TABLE `patient` (
`personal_number` INTEGER NOT NULL,
`first_name` VARCHAR(50) NOT NULL,
`last_name` VARCHAR(50) NOT NULL,
`insured` TINYINT(1) NOT NULL DEFAULT FALSE,
`admitted_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(`personal_number`)
);
Jeszcze należy dopisać szczegóły połączenia do bazy danych w properties naszej aplikacji. Dodatkowo, aby aplikacja się uruchomiła potrzeba ustawić właściwość spring.batch.jdbc.initialize-schema na ALWAYS. W innym wypadku dostaniemy błąd przy uruchomieniu: Table 'batch.BATCH_JOB_INSTANCE' doesn't exist. Jest to jedna z tabel niezbędna do zarządzania Jobami przez aplikację.
1
2
3
4
5
6
7
8
9
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/batch
username: root
password: xxx
batch:
jdbc:
initialize-schema: ALWAYS
Finalnie możemy uruchomić aplikację. Na starcie dostajemy informację, że nasz Job patientJob się uruchomił z property run.id=1. Następnie mamy log z naszego listenera i przechodzimy do uruchomienia kroku. Dalej w konsoli znajdujemy 20 wpisów na temat procesowania każdego z pacjentów. Po wszystkim idzie informacja, że Job się zakończył prawidłowo i jego wykonanie trwało 247ms.
...
2021-07-19 22:07:57.535 INFO 14600 --- [ main] p.d.batchdemo.BatchDemoApplication : Started BatchDemoApplication in 2.425 seconds (JVM running for 2.891)
2021-07-19 22:07:57.536 INFO 14600 --- [ main] o.s.b.a.b.JobLauncherApplicationRunner : Running default command line with: []
2021-07-19 22:07:57.659 INFO 14600 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=patientJob]] launched with the following parameters: [{run.id=1}]
2021-07-19 22:07:57.690 INFO 14600 --- [ main] pl.devcezz.batchdemo.PatientJobListener : -----> Job has started <-----
2021-07-19 22:07:57.740 INFO 14600 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [patientStep]
2021-07-19 22:07:57.786 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 334080
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 846884
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 702588
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 638872
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 742506
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 412592
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 557143
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 375846
2021-07-19 22:07:57.789 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 847630
2021-07-19 22:07:57.790 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 870814
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 600996
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 479311
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 726659
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 640314
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 371910
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 188741
2021-07-19 22:07:57.831 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 778174
2021-07-19 22:07:57.832 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 198717
2021-07-19 22:07:57.832 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 894628
2021-07-19 22:07:57.832 INFO 14600 --- [ main] p.d.batchdemo.PatientItemProcessor : Processing patient of personal number: 276626
2021-07-19 22:07:57.896 INFO 14600 --- [ main] o.s.batch.core.step.AbstractStep : Step: [patientStep] executed in 155ms
2021-07-19 22:07:57.917 INFO 14600 --- [ main] pl.devcezz.batchdemo.PatientJobListener : -----> Job has ended successfully <-----
2021-07-19 22:07:57.943 INFO 14600 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=patientJob]] completed with the following parameters: [{run.id=1}] and the following status: [COMPLETED] in 247ms
...
Wchodząc na MySQL zobaczymy, że do dyspozycji dostaliśmy wiele tabel poza naszą patient. Jedną z nich jest tabela z raportami uruchomień Jobów. Można z niej wyczytać kiedy został stworzony dany Job, kiedy się uruchomił, kiedy się skończył, jaki jest jego aktualny status oraz z jakim się zakończył.
mysql> select * from BATCH_JOB_EXECUTION;
+------------------+---------+-----------------+----------------------------+----------------------------+----------------------------+-----------+-----------+--------------+----------------------------+----------------------------+
| JOB_EXECUTION_ID | VERSION | JOB_INSTANCE_ID | CREATE_TIME | START_TIME | END_TIME | STATUS | EXIT_CODE | EXIT_MESSAGE | LAST_UPDATED | JOB_CONFIGURATION_LOCATION |
+------------------+---------+-----------------+----------------------------+----------------------------+----------------------------+-----------+-----------+--------------+----------------------------+----------------------------+
| 1 | 2 | 1 | 2021-07-19 22:07:57.599000 | 2021-07-19 22:07:57.670000 | 2021-07-19 22:07:57.917000 | COMPLETED | COMPLETED | | 2021-07-19 22:07:57.919000 | NULL |
+------------------+---------+-----------------+----------------------------+----------------------------+----------------------------+-----------+-----------+--------------+----------------------------+----------------------------+
1 row in set (0.00 sec)
Efektem naszej pracy jest uzupełniona tabela z danymi pacjentów.
mysql> select * from patient;
+-----------------+------------+------------+---------+-------------+
| personal_number | first_name | last_name | insured | admitted_at |
+-----------------+------------+------------+---------+-------------+
| 334080 | Jesse | Richards | 1 | 2021-07-19 |
| 846884 | Erin | Stewart | 1 | 2021-07-19 |
| 702588 | Glen | Stone | 1 | 2021-07-19 |
| 638872 | Bret | Young | 1 | 2021-07-19 |
| 742506 | Bev | Richards | 1 | 2021-07-19 |
| 412592 | Fran | Walsh | 1 | 2021-07-19 |
| 557143 | Sidney | King | 0 | 2021-07-19 |
| 375846 | Terry | Owen | 1 | 2021-07-19 |
| 847630 | Erin | Kelly | 1 | 2021-07-19 |
| 870814 | Gabby | Walsh | 1 | 2021-07-19 |
| 600996 | Ashley | Khan | 1 | 2021-07-19 |
| 479311 | Frankie | Kaur | 0 | 2021-07-19 |
| 726659 | Gale | Miller | 0 | 2021-07-19 |
| 640314 | Brice | Simpson | 1 | 2021-07-19 |
| 371910 | Skylar | Macdonald | 1 | 2021-07-19 |
| 188741 | Skye | Harvey | 0 | 2021-07-19 |
| 778174 | Franky | Parry | 1 | 2021-07-19 |
| 198717 | Jordan | Fox | 0 | 2021-07-19 |
| 894628 | Angel | Richardson | 1 | 2021-07-19 |
| 276626 | Jess | Harrison | 1 | 2021-07-19 |
+-----------------+------------+------------+---------+-------------+
20 rows in set (0.00 sec)
Podsumowanie
Przetwarzanie wsadowe to naprawdę potężne narzędzie jeżeli chcemy wykonać jakąś pracę bez udziału użytkownika. Dzięki Spring Batch nasza praca ogranicza się tylko do kilku ustawień konfiguracyjnych przez co w całości możemy poświęcić uwagę regułom biznesowym. Jeżeli, więc nie miałeś bądź nie miałaś okazji zapoznać się z tą metodą procesowania danych to zachęcam Cię do jej wypróbowania wykorzystując framework Springa.
Link do GitHuba: https://github.com/cezarysanecki/code-from-blog
Źródła:
- https://spring.io/guides/gs/batch-processing/
- https://nofluffjobs.com/blog/przetwarzanie-batch-owe-w-springu/
- https://www.toptal.com/spring/spring-batch-tutorial
- https://www.slideshare.net/jSessionPL/jsession-2-tomasz-gimbut-przetwarzanie-wsadowe-z-wykorzystaniem-spring-batch
- https://docs.spring.io/spring-batch/docs/current/reference/html/job.html
- https://stackoverflow.com/questions/58748891/spring-boot-rest-api-spring-batch