Ostatnimi czasy w mojej obecnej firmie niezbędne okazało się zbadanie wydajności wytwarzanej aplikacji. Głównie chodziło o czas jaki użytkownik musi poświęcić, aby uzyskać odpowiedź z serwera. Oczywiście składową tego czasu może być przetwarzanie danych przez język oprogramowania czy też odpytywanie innych zewnętrznych serwisów. Naszym zadaniem było zastosować dostępne narzędzie z innego projektu, które opierało się na wykorzystaniu adnotacji nad wybranymi metodami. Zapraszam do następnego artykułu z serii CaseStudy, gdzie przyjrzymy się zbieraniu metryk z aplikacji.
Przyjrzenie się problemowi
Załóżmy, że nasz serwis wygląda tak jak na niżej załączonym obrazku. Użytkownik wysyła żądanie HTTP, które jest odbierane przez serwer. Następnie odpytywane są trzy zewnętrzne komponenty, ich odpowiedzi są odpowiednio przetwarzane i wysyłana jest odpowiedź do żądającego.

Przykładowe działanie serwisu i jego zewnętrzne zależności
Taka aplikacja idzie na produkcję i po kilku dniach uzyskujemy informację, że czas oczekiwania na odpowiedź jest strasznie długi. Długo nie myśląc dochodzimy do wniosku, że potrzebujemy jakichkolwiek danych, aby zweryfikować co jest problemem. Najprostszym sposobem może okazać się użycie np. DevTools Chrome, który w zakładce Network pokazuje informacje zawierające czasy żądania.
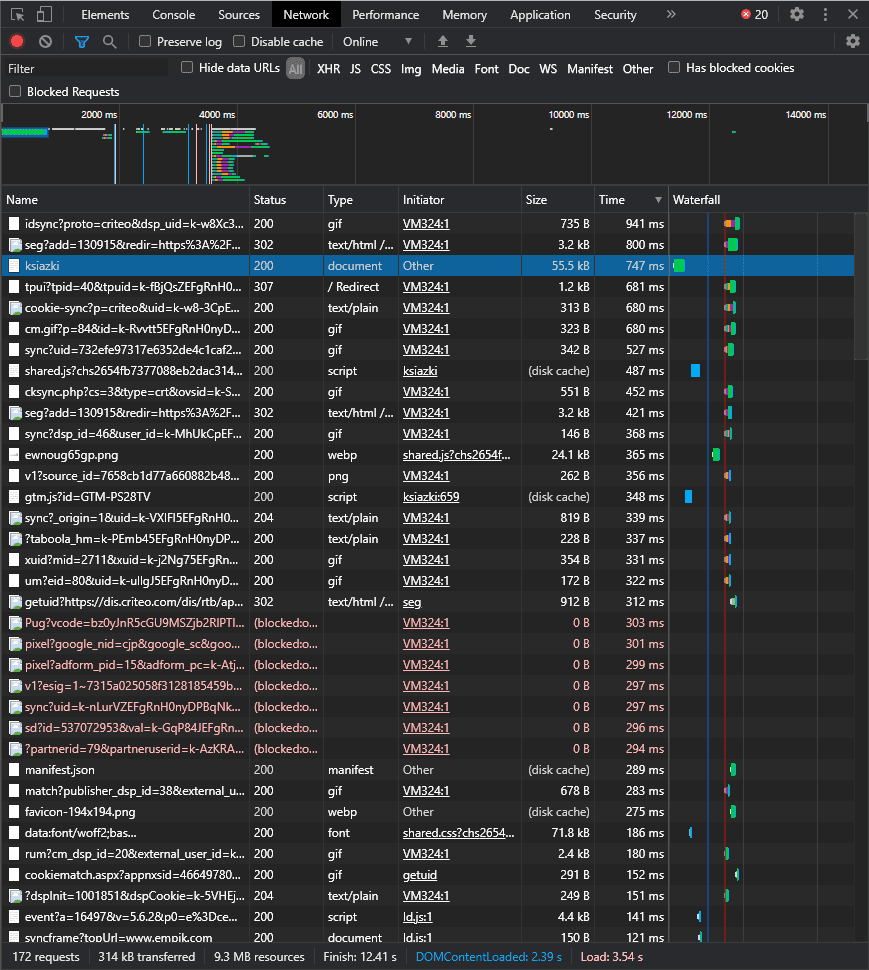
Przykład działania DevTools Chrome
Jest to dobre rozwiązanie, aby uzyskać szybką informację zwrotną. Jednak to narzędzie nie wskaże nam krytycznej części obsługi żądania, gdy np. problem leży po stronie implementacji. Z tego powodu przy projekcie, nad którym pracuję w firmie wykorzystaliśmy następujące oprzyrządowanie:
Własne adnotacje projektowe
Do wykorzystania mamy dwie adnotacje: pierwsza z nich używana jest głównie do oznaczenia endpointów, natomiast druga umieszczana jest nad metodami znajdującymi się w głębszych warstwach. Jeśli metoda oznaczona jedną z tych adnotacji zostanie wywołana to uruchamia się aspekt włączający pomiar czasu. Po zakończeniu pracy w metodzie zegar jest wyłączany, a wynik wysyłany jest do serwera gromadzącego informacje. Prawda, że prosty mechanizm? Należy jednak wspomnieć o kilku ograniczeniach i niedogodnościach.
Wszystkie adnotacje muszą zawierać literał, aby później bez problemu można było określić co ile czasu zajęło. Jednak musimy dbać o to, aby te informacje umieścić w pliku application.properties. Wszystko odbywa się ręcznie, więc istnieje duży wpływ czynnika ludzkiego na wynik już na samym początku pracy. Jeśli zapomnimy wpisać jednego z literałów to po prostu się nam nie odłoży czas wykonania dla tej metody. Dodatkowo dokładnie kolejnych poziomów adnotacji jest także niewygodne. Załóżmy, że istnieje sytuacja taka jak przedstawiona poniżej.

Wywoływania kolejnych poziomów klas
Załóżmy, że ‘Klasa 1’ zawiera metodę określającą nasz endpoint, którą oznaczyliśmy pierwszą adnotacją. Następnie wywoływana jest metoda z ‘Klasy 2’, którą oznaczamy drugą adnotacją. Co natomiast z ‘Klasą 3’? Możemy jej metodę także oznaczyć drugą adnotacją, natomiast trzeba wtedy zastosować pewien trick. Literał należy skonstruować jako złączenie oznaczenia metody ‘Klasy 2’ i nowego określania przy użyciu kropki czyli np. ‘metod2.metoda3’. Gdybyśmy tego nie zastosowali to w metrykach nie wiedzielibyśmy, że ‘metoda3’ znajduje się pod ‘metodą2’. Dodatkowo jeśli robi się spora pajęczyna wywołań w aplikacji to naprawdę ciężko nad tym zapanować i może dojść do wielu niejasności.
Ograniczeniem także jest samo użycie aspektów w Springu, a dokładniej w beanach. Chodzi o to, że aspekty są aplikowane do tworzącego się proxy wokół beana. W takiej sytuacji nie jest możliwe odłożenie się metryk, gdy jednak metoda z klasy wywołuje drugą metodę z tej samej klasy. Oczywiście obydwie są oznaczone adnotacjami.
Wykorzystanie Graphite
Następnym krokiem jest składowanie uzyskanych danych. Na naszym projekcie służy do tego Graphite. Według oficjalnej strony ma on do wykonania dwa zadania: przechowywać liczbowe dane serii czasowych oraz renderować je na żądanie. U nas jak wspomniałem pełni tylko tą pierwszą funkcję, chociaż producenci zastrzegają, że “Graphite is not a collection agent, but it offers the simplest path for getting your measurements into a time-series database.”
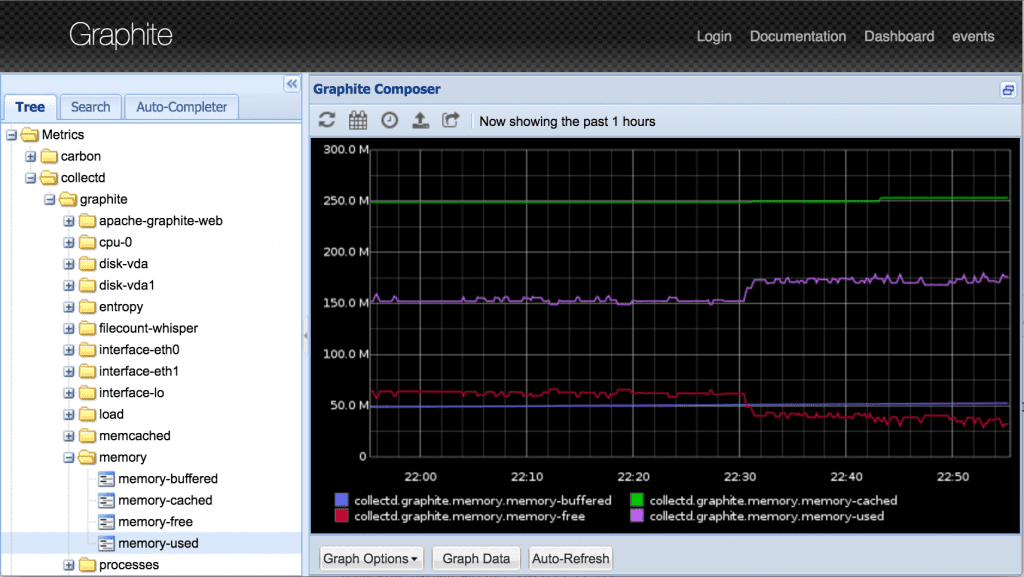
Przykład zagregowanych danych w Graphite wraz ze stworzonym wykresem
Sam Graphite posiada szeroką gamę integracji z innymi narzędziami, w tym właśnie z Grafaną. W ten sposób uzyskujemy dużo większe pole manewru tworzenia tablic i paneli do przeprowadzenia analizy.
Prezentacja danych w Grafanie
Jak można zaobserwować poniżej Grafana pozwala na kreacje szerokiej palety wykresów. Konfiguracja tabel i grafik nie sprawia najmniejszych problemów. Jednak według mnie utworzenie tego czego potrzebujemy może być problematyczne, czyli czasochłonne. Tak jak w naszym przypadku - średnich czasów wykonania metod.
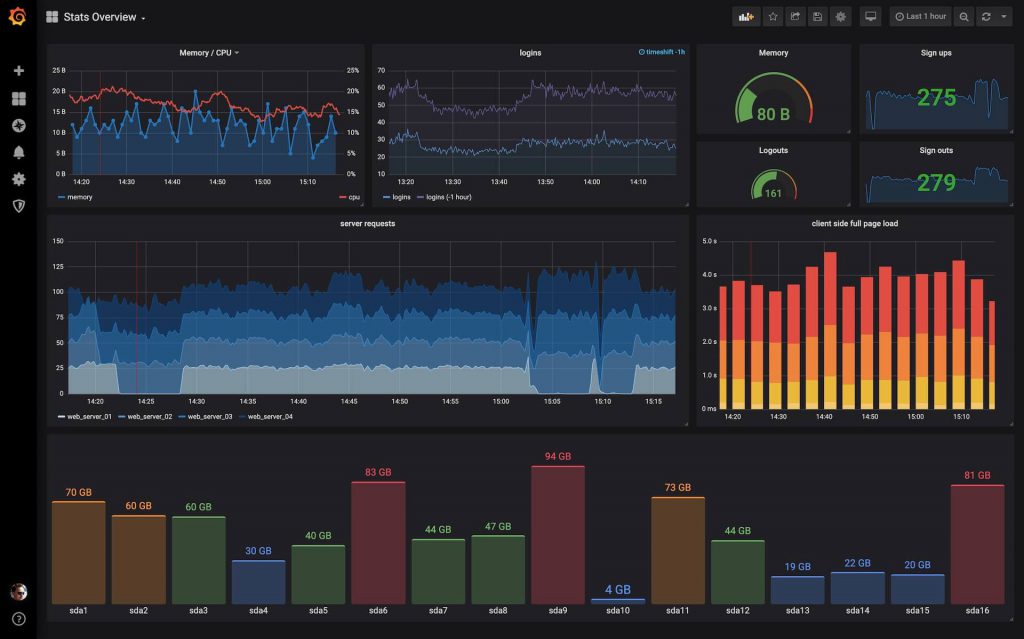
Dodatkowo nie do końca wiem czy utworzone wykresy można wyeksportować do postaci, która jest łatwa w obróbce. Zależy nam najbardziej na porównaniu wyników testów z różnych okresów czasowych. Eksport jest konieczny z racji tego, że nie do końca wiem jak ustawić dwa horyzonty czasowe na panelu. Chodzi o wybranie przykładowo okresów ‘2020-01-30 15:00 - 2020-01-30 16:00’ oraz ‘2020-01-30 18:00 - 2020-01-30 19:00’ w celu zestawienia ich na jednym wykresie.
Przemyślenia związane z rozwiązaniem
Jest to tylko krótki opis narzędzi oraz sposobu ich użycia na projekcie. Zastanawiam się tylko czy są one odpowiednio dobrane do stawianych wymagań. Posiadając jeden endpoint w serwisie obsługujący różne typy obiektów ciężko jest dokonać testów wydajnościowych dla jednego z nich. Gdy w trakcie naszej pracy druga osoba wyśle żądanie do naszego serwisu z innym typem obiektu niż właśnie jest w trakcie badania to nasze testy przestają być użyteczne. Mamy anomalię, która utrudnia interpretację wyników. Dodatkowo sprawy nie ułatwia fakt, że nie ma dedykowanego środowiska to przeprowadzenia takich testów. Dlatego mam pytanie, czy jest to problem dobrania narzędzi testowych czy samej implementacji serwisu? Czy sposób przeprowadzenia testów wydajnościowych powinien mieć wpływ na architekturę? Czy to jednak trudności w badaniu aplikacji świadczą o tym, że jednak implementacja nie jest do końca poprawna? Daj znać co o tym myślisz!
Podsumowanie
Poprzednim razem skupiliśmy się na problemie związanym z datami w Javie. Mam nadzieję, że ten artykuł również zachęcił Was do przemyśleń oraz eksperymentów z narzędziami dostępnymi na rynku. Dla mnie aspekt testów wydajnościowych nie jest jeszcze do końca znany. Nie czuję jeszcze kiedy można powiedzieć, że testy można uznać za miarodajne i służą jako podstawa do wyciągania wniosków. Jednak ciągle się uczę i mam nadzieję, że w przyszłości będę w stanie taką wiedzę zdobyć!
Powodzenia i cześć!