Przeglądając ostatnimi czasy media społecznościowe coraz częściej natrafiam na wpisy oraz reklamy o GraphQL. Na początku pomijałem je z premedytacją, ale wraz ze wzrostem ich pojawiania się w propozycjach dla mnie, ugiąłem się i spojrzałem co się kryje za tym pojęciem. Muszę przyznać, że zostałem miło zaskoczony koncepcją, która wydaje się przejrzysta w stosowaniu mimo zapoznawania się z nią tylko przez pół godziny. Nawet można pokusić się wręcz o taką tezę czy GraphQL może stać się godnym następcą REST? Projekt w tej chwili ma trochę ponad 6 lat, ale i tak ciężko taki stan rzeczy przewidzieć. Moim zdaniem ma ku temu dobre argumenty, sprawdźmy!
Czym w ogóle jest GraphQL?
GraphQL jest to open-sourcowy język służący do obsługi zapytań oraz manipulacji danymi dla interfejsu API. Dodatkowo jest także środowiskiem wykonawczym, w którym można wysyłać żądania o istniejące dane. Początki GraphQL sięgają roku 2012, kiedy to został opracowany przez Facebooka do ich wewnętrznego użytku. Dopiero w 2015r. ujrzał on światło dzienne, a w listopadzie 2018r. został przeniesiony z Facebooka do nowo utworzonej grupy GraphQL Foundation. GraphQL ma oferować większą elastyczność oraz dokładność w porównaniu do jego rywala, REST.
Dlaczego w ogóle powstał GraphQL? Jego główną przyczyną stworzenia były ograniczenia, na które napotykało API tworzone jako REST. GraphQL pozwala deweloperom na tworzenie żądań, które wyciągają dane z wielu źródeł za pomocą jednego wywołania API. Pozwól, że przedstawię Ci problem jaki możemy napotkać tworząc interfejs przy pomocy REST.
Studium przypadku
Załóżmy, że mamy aplikację posiadającą dane o klubach piłkarskich. Chcielibyśmy pozyskać informacje o danym klubie poprzez wywołanie endpointu /clubs/:id. Zobaczymy jak może wyglądać przykładowe zapytanie wraz z odpowiedzią.
1
2
3
4
5
6
7
8
9
10
Request: GET /clubs/245
Response:
{
"id": 245,
"name": "Watford Football Club",
"country": "England",
"league": "Championship",
"founded": 1881,
"players": [ ... ]
}
Wszystko wygląda dobrze, ale co w przypadku gdybyśmy chcieli uzyskać mniej informacji o klubie do np. zaprezentowania w tabeli. Możemy dodać parametr w URL, w którym podamy pola, które nas interesują.
1
2
3
4
5
6
7
Request: GET /clubs/245?fields=id,name,league
Response:
{
"id": 245,
"name": "Watford Football Club",
"league": "Championship",
}
Nie jest to w sumie najgorsze rozwiązanie, ale problem pojawia się w przypadku, gdy chcielibyśmy pobrać tylko częściowe dane piłkarzy danego klubu. Można by było stworzyć kolejny endpoint pokroju /clubs-with-short-info-players/:id czy też odpytać dwukrotnie serwer o dane. Zawsze można też pobrać wszystkie dane z /clubs/:id i wyświetlić tyle te pola, które są nam niezbędne. Jednak takie rozwiązanie powoduje duży narzut wydajnościowy z racji pobrania zbędnych danych. Co na to GraphQL?
GraphQL to the rescue!
GraphQL stawia tylko na jeden endpoint, który wykorzystuje do wymiany danych. Wysyłając zapytanie przekazujemy strukturę danych z niezbędnymi dla nas polami. Konsekwencją tego jest uzyskanie odpowiedzi zawierającej tylko te dane, które są nam potrzebne. Tylko jak to wygląda w praktyce? Wyślijmy ponownie zapytanie, ale tym razem z wykorzystaniem GraphQL.
GraphQL request: /__grapphql
query {
clubs {
id
name
country
players {
name
age
position
}
}
}
W odpowiedzi uzyskujemy tylko te pola, które nas interesują w danej chwili. Nie musimy robić nic więcej, filtrowanie niezbędnych informacji o klubach pozostawiamy w rękach GraphQL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"data": {
"clubs": [
{
"id": 245,
"name": "Watford Football Club",
"country": "England",
"players": [
{
"name": "Ben Foster",
"age": 37,
"position": "GK"
},
{
"name": "João Pedro",
"age": 19,
"position": "ST"
},
...
]
},
...
]
}
}
Na mnie robi to duże wrażenie z racji tego, że nie muszę martwić się o kolejne endpointy, które mogą się różnić niewielką częścią. Spójrzmy zatem co składa się na bebechy GraphQL pozwalające nam na definiowanie takiego API.
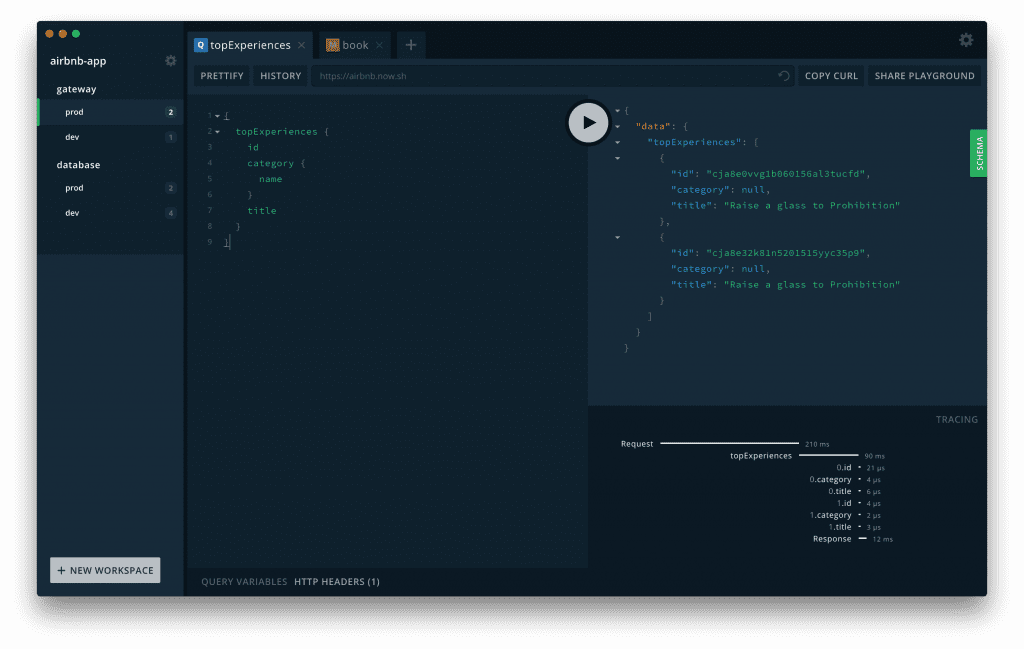
GraphQL Playgroung - możliwość przetestowania daje szersze spojrzenie
Co w GraphQL siedzi
Należy użyć odpowiednich mechanizmów GraphQL, aby odpowiednio zaimplementować niezbędne nam API. Na ten proces dostrajania składają się trzy główne koncepcje.
- Queries
- Resolvers
- Schema
Queries
W celu komunikacji poprzez GraphQL musimy oprzeć się właśnie na zapytaniach. Definiujemy je w podobny sposób jak to było przedstawione wyżej, czyli rozpoczynamy od słowa kluczowego query. Następnie uszczegóławiamy nazwy interesujących nas właściwości zasobów. Podaje się je w podobnej składni jaką możemy spotkać w JSON. Gdy odpytamy serwer w ten sposób otrzymamy odpowiedź w postaci obiektu JSON, który będzie miał identyczną strukturę jak nasze zapytanie, ale będzie wypełniony danymi.
Resolvers
Sam GraphQL jest tylko narzędziem, które musimy dostosować do naszego problemu. Nie potrafi on sam z siebie określić gdzie znajdują się dane, na których będziemy operować. Z tego powodu musimy wykorzystać mechanizm nazywany właśnie resolvers, aby wskazać GraphQL skąd ma pobierać dla nas dane.
Schema
Niezbędne jest także określenie struktury naszego API, w tym celu trzeba zdefiniować schemat. Dzięki niemu opiszemy strukturę naszego endpointu oraz typ danych jego składowych. Do tego posłuży nam SDL, czyli Schema Definition Language, dzięki któremu nie musimy martwić się komunikacją pomiędzy programistami frontendowymi oraz backendowymi. Posługując się nim można wszystko jasno i klarownie opisać, a także każdy może uzyskać dostęp do takiego schematu.
Podsumowanie
Muszę przyznać, że jestem bardzo zaciekawiony działaniem tego rozwiązania i na pewno wykorzystam go kiedyś do jednego ze swoich projektów. Polecam przyjrzeć się GraphQL Playgound, dzięki któremu możemy zapoznać się z podstawowymi mechanizmami GraphQL poprzez własnoręczne klikanie. Znalazłem także rozwiązanie, które pozwala na wykorzystanie GraphQL w Springu, więc tym bardziej jestem zdeterminowany do zabawy z nim! Mam nadzieję, że zaciekawiłem Cię tym wpisem i chciałbym poznać Twoje zdanie czy GraphQL może stać się godnym następcą REST?