Nigdy nie miałem możliwości programować w sposób reaktywny aż w końcu postanowiłem bliżej przyjrzeć się temu zagadnieniu. W tym celu skorzystałem z jednego z modułów dostarczanego przez framework Spring’a zwanego Spring WebFlux. Programowanie reaktywne jest asynchronicznym paradygmatem programowania, który przetwarza strumienie danych w sposób nieblokujący (np. poprzez wykorzystanie nieblokujących serwerów). Asynchroniczny oznacza, że odbiorca niekoniecznie musi odebrać wiadomość w momencie jej wysłania. Nieblokujący natomiast określa sytuację, w której wątki nie mogą na siebie czekać, czyli muszą być od siebie niezależne (brak bezczynności). W tym celu wykorzystuje się narzędzia np. serwer Netty, który pochodzi z rodziny serwerów nieblokujących (trzeba o tym koniecznie pamiętać!).
Dodatkowo należy zaznaczyć, że programowanie reaktywne wykorzystuje elementy funkcyjnych języków programowania. Dzięki takiemu rozwiązaniu można tworzyć skalowane oraz wydaje aplikacje.
Koncepcja programowania reaktywnego
Samo podejście programowania reaktywnego wywodzi się od wzorca projektowego Obserwator (tutaj znajdziecie jego dobre wytłumaczenie). W tym podejściu opieramy się na eventach, które przekazujemy pomiędzy Publisherem a Subscriberem.
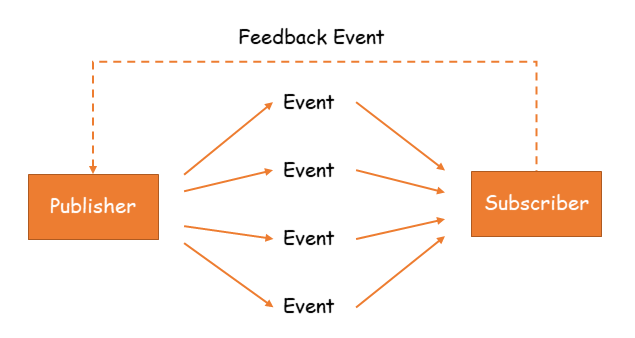
Nasz Subscriber oczekuje na zdarzenie wyemitowane przez obserwowanego przez siebie Publishera. Gdy dane zostaną wysłane to od razu je pozyska. Taka komunikacja jest ciągła i trwa do końca aktywności subskrypcji. Istnieje też sytuacja, gdy to Subscriber będzie chciał poinformować o czymś Publishera. Wtedy taka komunikacja zachodzi na żądanie (tzw. Backpressure). Wysyłany jest feedback, który może zawierać takie informacje jak:
- brak możliwości nadążania za wysyłanymi wiadomościami z prośbą o zmniejszenie intensywności
- błędy powstałe podczas przetwarzania danych
Różnice pomiędzy podejściem klasycznym a reaktywnym
W przypadku blokującego serwera wątek, który wysyła żądanie musi oczekiwać na odpowiedź od serwera np. łączącego się z bazą danych. Przez to jest on bezczynny do momentu, w którym request nie zostanie obsłużony. W podejściu nieblokującym wątek odpowiedzialny za przetworzenie żądania nie czeka tylko przekazuje jego obsługę do specjalnej puli wątków, a sam działa dalej. Gdy przychodzi odpowiedź na request wątek delegujący zadanie dowiaduje się o jego ukończeniu i może taką wiadomość przekazać do Subscribera. Taki sposób obsługi żądań jest wydajniejszy z powodu lepszego wykorzystania dostępnej puli wątków. W architekturze mikroserwisowej może mieć to wielkie znaczenie z racji tego, że aplikacja zużywa mniej zasobów przez co może działać stabilniej.
Przykład zastosowania
Poniżej zaprezentowałem kawałek kodu z framework’a Spring WebFlux, który ma za zadanie stworzyć kluby piłkarskie z ligi angielskiej. Następnie powinien zapisać je do bazy danych. Aplikacja dodatkowo ma dodać jeszcze jeden z klubów, który nie należy do tej rodziny. Operujemy w tym przypadku na strumieniach należących do WebFlux’a - Flux (obsługuje od 0 do n elementów) i Mono (obsługuje od 0 do 1 elementu).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@EventListener(ApplicationReadyEvent.class)
public void insertInitialData() {
clubRepo.deleteAll()
.thenMany(
Flux.just(
"Arsenal", "Aston Villa", "Brighton & Hove Albion", "Burnley",
"Chelsea", "Crystal Palace", "Everton", "Fulham", "Leeds United",
"Leicester City", "Liverpool", "Manchester City",
"Manchester United", "Newcastle United", "Sheffield United",
"Southampton", "Tottenham Hotspur", "West Bromwich Albion",
"West Ham United", "Wolverhampton Wanderers"
)
)
.map(Club::new)
.flatMap(clubRepo::save)
.thenMany(clubRepo.findAll())
.subscribe(System.out::println);
Mono.just("FC Barcelona")
.map(Club::new)
.flatMap(clubRepo::save)
.subscribe();
}
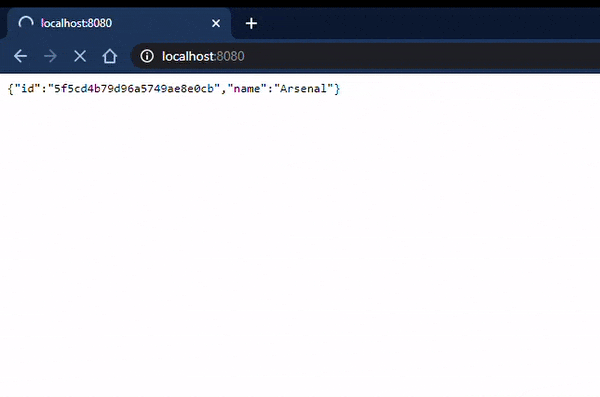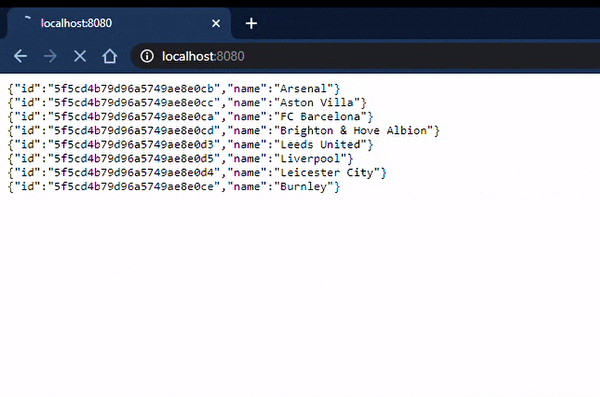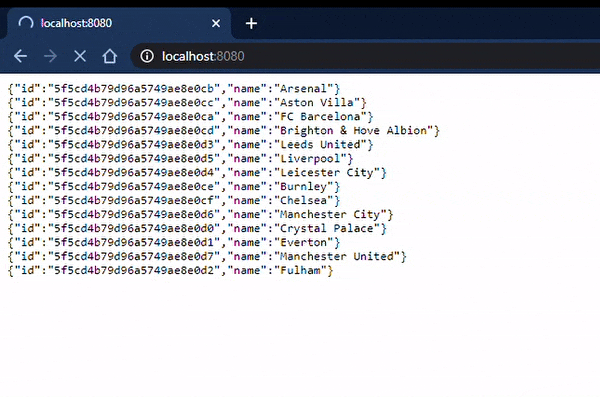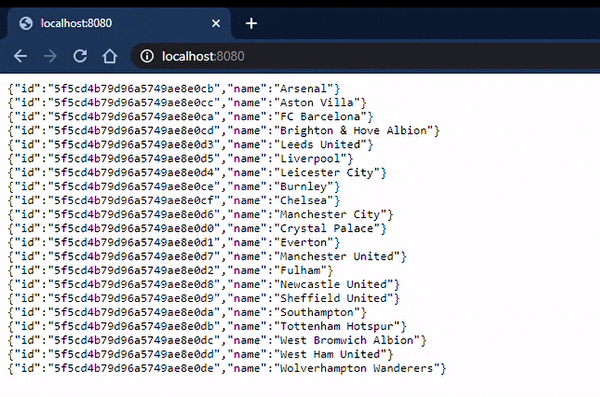
Poniżej prezentuję co wyświetliła nam nasza aplikacja:
Club{id='5f5cd6433b23a034bc05ba96', name='Arsenal'}
Club{id='5f5cd6433b23a034bc05ba97', name='Aston Villa'}
Club{id='5f5cd6433b23a034bc05ba95', name='FC Barcelona'}
Club{id='5f5cd6433b23a034bc05ba98', name='Brighton & Hove Albion'}
Club{id='5f5cd6433b23a034bc05ba99', name='Burnley'}
Club{id='5f5cd6433b23a034bc05ba9c', name='Everton'}
Club{id='5f5cd6433b23a034bc05ba9b', name='Crystal Palace'}
Club{id='5f5cd6433b23a034bc05baa1', name='Manchester City'}
Club{id='5f5cd6433b23a034bc05ba9a', name='Chelsea'}
Club{id='5f5cd6433b23a034bc05baa2', name='Manchester United'}
Club{id='5f5cd6433b23a034bc05baa3', name='Newcastle United'}
Club{id='5f5cd6433b23a034bc05baa0', name='Liverpool'}
Club{id='5f5cd6433b23a034bc05baa4', name='Sheffield United'}
Club{id='5f5cd6433b23a034bc05baa5', name='Southampton'}
Club{id='5f5cd6433b23a034bc05baa6', name='Tottenham Hotspur'}
Club{id='5f5cd6433b23a034bc05ba9d', name='Fulham'}
Club{id='5f5cd6433b23a034bc05ba9e', name='Leeds United'}
Club{id='5f5cd6433b23a034bc05ba9f', name='Leicester City'}
Club{id='5f5cd6433b23a034bc05baa7', name='West Bromwich Albion'}
Club{id='5f5cd6433b23a034bc05baa8', name='West Ham United'}
Club{id='5f5cd6433b23a034bc05baa9', name='Wolverhampton Wanderers'}
Jak widać FC Barcelona znalazła się w konsoli mimo tego, że miała być, według kodu, zapisana później do bazy danych 🤯. To jest właśnie moc programowania reaktywnego! Główny wątek nie zwleka aż wszystkie rekordy zostaną zapisane, od razu działa z dalszą częścią kodu. Dopiero, gdy zapisywanie zostanie zakończone wraca do odczytania i wyświetlenia wszystkich klubów.
Dodatkowo przy tworzeniu endpoint’u można zauważyć, że dzięki zmiennej MediaType.APPLICATION_STREAM_JSON_VALUE w adnotacji np. @GetMapping(produces = MediaType.APPLICATION_STREAM_JSON_VALUE) otrzymujemy pojedyncze rekordy w chwili ich przetworzenia. Nie czekamy aż cały strumień zostanie obrobiony i dane będą zwrócone jako jeden zestaw. Spróbuj wykonać u siebie taki eksperyment bez tej zmiennej i sprawdź co się stanie.
1
2
3
4
5
@GetMapping(produces = MediaType.APPLICATION_STREAM_JSON_VALUE)
public Flux<Club> getAllClubs() {
return clubRepo.findAll()
.delayElements(Duration.ofMillis(500));
}
Na koniec chciałbym zaznaczyć, że ten typ pisania aplikacji jest bardziej skomplikowany od tradycyjnego (imperatywnego) podejścia, który jest bardziej zrozumiały i naturalny. Dodatkowo wiele bibliotek działa w sposób blokujący na co trzeba bardzo uważać. Dlatego jeśli klasyczny Spring MVC się sprawdza to nie ma co kombinować i należy postawić na działające rozwiązanie. Niepotrzebne komplikacje mogą przynieść tylko więcej strat niż korzyści. Trzeba się dwa razy dobrze zastanowić przed zmianą podejścia.
Podsumowanie
Ten artykuł to moje pierwsze starcie z programowaniem reaktywnym, więc z chęcią dowiem się czy moje zrozumienie tematu jest zgodne z prawdą. Podziel się swoją opinią w komentarzu lub napisz do mnie jeśli choć trochę zaciekawiłem Cię tą koncepcją bądź chciałbyś sprostować pewne niedociągnięcia 😉.